






摘要:图,连通网,最小生成树,Prim算法,Java实现Prim
一、相关概念
首先,我们得理解啥是最小生成树以及图的相关定义
- 连通图:在无向图中,若任意两个顶点vi与vj都有路径相通,则称该无向图为连通图。
- 强连通图:在有向图中,若任意两个顶点vi与vj都有路径相通,则称该有向图为强连通图。
- 连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接连个顶点的代价,称这种连通图叫做连通网。
- 生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。
- 最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
由上可知,最小生成树是对于连通网的,举个例子,如下所示:
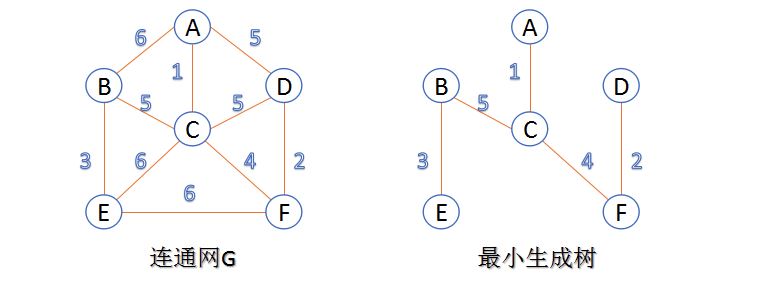
我们知道,最小生成树的算法通常有两种:Kruskal算法和Prim算法。这两种算法都是属于贪心算法。这篇博文研究的是Prim算法。
二、最小生成树的形成
怎么找到最小生成树呢,其实不管是Kruskal算法还是Prim算法都是一个原理:找到一条轻量级边,举个简单例子,我们一个联通图的节点集合Q,和他的最小生成树A,那么树A中的节点与集合Q中的权重最小的边就为轻量级边,该轻量级边横跨了集合Q和树A,一定是属于最小生成树的,所以可以把该轻量级边在Q中的节点加入到最小生成树A中。具体原理以及证明请查看:算法导论第三版第六部分图算法最小生成树(625~628页)。因为篇幅原因,这里不做过多说明,总之Kruskal和Prim都是基于这个原理的。
三、Prim算法
Prim算法可以称为是“加点法”,不过本质上还是选择一条轻量级边,它具有的一个性质是集合A中的边总是构成一颗树。这棵树从一个任意的根节点r开始,一直长大到覆盖V中的所有节点位置。算法每一步在连接集合A和A之外的节点的所有边中,选择一条轻量级边加入到A中。本策略属于贪心策略,因为每一步所加入的边都必须是使树的总权重增加量最小的边。
算法伪代码如下:
MST-PRIM(G,w,r)for each u <- G.Vu.key=∞u.π =NILr:key=0Q=G.Vwhile Q≠Ou=EXTRACT-MIN(Q)for each v <- G.Adj[u]if v<-Q and w(u,v)<v.keyv.π=uv.key=w(u,v)DECREASE-KEY(Q,v)A=A∪{u}
在上面的伪代码中,所有不在树A中的节点全部都存放在一个基于key属性的最小优先队列Q中,对于每个节点v,属性v.key保存的是连接v和树中节点所有边中最小权重的边,我们约定若不存在这样子的边,则u.key=∞。属性v.π给出的是节点v在树中的父节点。
举个例子
有如下连通网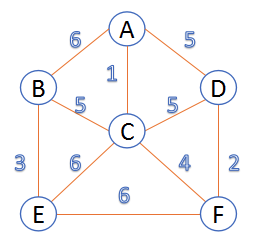
根据上面的伪代码来运行
第一步:初始化A和优先队列Q
A={},Q={A,B,C,D,E,F}A.Key=0;A.π=NilB.Key=∞;B.π=NilC.Key=∞;C.π=NilD.Key=∞;D.π=NilE.Key=∞;E.π=NilF.Key=∞;F.π=Nil
第二步:从Q中取出A来,更新各个节点到树A的距离,以及保证Q还是优先队列
A={A},Q={C,B,D,E,F}A.key=0;A.π=NILB.key=6;B.π=AC.key=1;C.π=AD.key=5;D.π=AE.key=∞;E.π=NILF.key=∞;F.π=NIL
第三步:从Q中取出C来,更新各个节点到树A的距离,以及保证Q还是优先队列
A={A,C},Q={F,B,D,E}A.key=0;A.π=NILC.key=1;C.π=AB.key=5;B.π=CD.key=5;D.π=AE.key=6;E.π=CF.key=4;F.π=C
第四步:从Q中取出F来,更新各个节点到树A的距离,以及保证Q还是优先队列
A={A,C,F},Q={D,B,E}A.key=0;A.π=NILC.key=1;C.π=AF.key=4;F.π=CB.key=5;B.π=CD.key=2;D.π=FE.key=6;E.π=C
第五步:从Q中取出D来,更新各个节点到树A的距离,以及保证Q还是优先队列
A={A,C,F,D},Q={B,E}A.key=0;A.π=NILC.key=1;C.π=AF.key=4;F.π=CD.key=2;D.π=FB.key=5;B.π=CE.key=6;E.π=C
第七步:从Q中取出B来,更新各个节点到树A的距离,以及保证Q还是优先队列
A={A,C,F,D,B},Q={E}A.key=0;A.π=NILC.key=1;C.π=AF.key=4;F.π=CD.key=2;D.π=FB.key=5;B.π=CE.key=3;E.π=B
第八步:从Q中取出E来,更新各个节点到树A的距离,以及保证Q还是优先队列
A={A,C,F,D,B,E},Q={}A.key=0;A.π=NILC.key=1;C.π=AF.key=4;F.π=CD.key=2;D.π=FB.key=5;B.π=CE.key=3;E.π=B
第九步:Q为空,结束。
由上面可以知道,根据伪代码中的逻辑,成功生产了图的最小生成树,我们现在聊分析下算法的复杂度!
四、Prim算法时间复杂度分析
我们现在来重新砍一下Prim算法,把上面的伪代码拷贝下来
MST-PRIM(G,w,r)for each u <- G.Vu.key=∞u.π =NILr:key=0Q=G.Vwhile Q≠Ou=EXTRACT-MIN(Q)for each v <- G.Adj[u]if v<-Q and w(u,v)<v.keyv.π=uv.key=w(u,v)DECREASE-KEY(Q,v)A=A∪{u}
算法的2~6行是建堆,我们知道最小优先队列的初始化时间成本为O(V)。因为有V个节点,所以while循环要执行V次,从最小优先队列中取出堆顶元素时间成本为O(lgV),所以第8行的总时间成本为O(VlgV)。因为邻接矩阵的边为2E,所以9~13行总执行次数为O(E),在for循环里,我们可以在常数时间里完成对一个节点是否属于Q,方法就是对每个节点维护一个标志位来指明该节点是否属于Q,并在将节点从Q中删除的时候对该标志位进行更新。在算法12行因为改变了节点的key值,所以需要重新建堆,该操作在二叉最小堆上执行的时间成本为O(lgV)。因此第9~13行的总执行时间成本为O(ElgV)。所以Prim算法的总时间代价为O(V+VlgV+ElgV)=O(ElgV)。如果用斐波那契堆来实现最小优先队列Q,Prim算法的渐进运行时间可以进一步得到改善。
五、Java实现
我们这里用Java来实现Prim算法,根据上面的伪代码我们知道,我们需要实现一个最小优先队列,这里用最小堆来实现,代码如下:
/***最小堆实现的一个优先队列* @author suibibk@qq.com*/class PriorityQueue<E extends Comparable<E>> {//这里使用数组来实现private ArrayList<E> data;public PriorityQueue(int capacity) {data = new ArrayList<>(capacity);}public PriorityQueue() {data = new ArrayList<>();}//返回堆中元素的个数public int getSize() {return data.size();}//返回二叉树中索引为index的节点的父节点索引public int parent(int index) {if(index == 0) {throw new IllegalArgumentException("index-0 dosen't have parent");}return (index-1)/2;}//返回完全二叉树中索引为index的节点的左孩子的索引private int leftChild(int index) {return index*2+1;}//返回完全二叉树中索引为index的节点的右孩子的索引private int rightChild(int index) {return index * 2 + 2;}//交换索引为i、j的值private void swap(int i, int j) {E t = data.get(i);data.set(i, data.get(j));data.set(j, t);}//向堆中添加元素public void add(E e) {data.add(e);siftUp(data.size() - 1);}//上浮private void siftUp(int k) {//k不能是根节点,并且k的值要比父节点的值小while (k > 0 && data.get(parent(k)).compareTo(data.get(k)) > 0) {swap(k, parent(k));k = parent(k);}}//看堆中最小的元素public E findMin() {if (data.size() == 0)throw new IllegalArgumentException("Can not findMax when heap is empty");return data.get(0);}//取出堆中最小的元素public E extractMin() {E ret = findMin();swap(0, data.size() - 1);data.remove(data.size() - 1);siftDown(0);return ret;}/*** 当修改了堆中一些元素后,要执行先向下浮再向上浮的操作,这里需要重新建堆*/public void rebuildHead(E e) {// 这里优化为在建优先队列的时候,就指定节点在优先队列中的坐标,那么就不需要使用循环for (int j = 0; j < data.size(); j++) {if(e==data.get(j)) {siftDown(j);siftUp(j);break;}}}//下浮private void siftDown(int k) {//leftChild存在while (leftChild(k) < data.size()) {int j = leftChild(k);//rightChild存在,且值小于leftChild的值if (j + 1 < data.size() &&data.get(j).compareTo(data.get(j + 1)) > 0)j = rightChild(k);//data[j]是leftChild和rightChild中最小的if (data.get(k).compareTo(data.get(j)) <0)break;swap(k, j);k = j;}}//取出堆中最大的元素,替换为元素epublic E replace(E e){E ret = findMin();data.set(0, e);siftDown(0);return ret;}//heapify操作:将数组转化为堆public PriorityQueue(E[] arrs) {data = new ArrayList<>(Arrays.asList(arrs));for (int i = parent(data.size() - 1); i >= 0; i--) {siftDown(i);}}public void print() {for (E e : data) {System.out.print(" "+e);}}public List<E> getDate() {return data;}}
该队列初始化的复杂度为O(V),取出队头的复杂度为O(lgV),重新建堆的复杂度为O(lgV),满足伪代码中的要求。
然后我们需要有一个节点对象,该对象不仅仅是当做图的节点,还要当做树A中的节点以及最小优先队列Q中的节点,所以不仅仅需要节点名称,还需要父节点,以及key属性,以及一个标志位表明是否存在Q中(这是为了让这个判定复杂度变为O(1))。
//图的节点,当然也是最小优先队列Q的节点,也是最小生成树A的节点:因此多了属性key,parent,inQclass Node implements Comparable<Node>{private int index;//坐标private int key;//每个节点的key属性private String value;//节点名称private Node parent;//父节点private int inQ=1;//是否属于Q,默认是属于的,等离开才不属于@Overridepublic int compareTo(Node o) {return this.key-o.key;}public Node(String value) {super();this.value = value;}public int getIndex() {return index;}public void setIndex(int index) {this.index = index;}public int getKey() {return key;}public void setKey(int key) {this.key = key;}public String getValue() {return value;}public void setValue(String value) {this.value = value;}public Node getParent() {return parent;}public void setParent(Node parent) {this.parent = parent;}public int getInQ() {return inQ;}public void setInQ(int inQ) {this.inQ = inQ;}}
然后我们需要一个图对象,可以方便的通过某一个节点找到相邻的节点,这里用的是邻接矩阵来存储图:
//定义图:无向图class Graph{//顶点数目int size;int index=0;//顶点private List<Node> vertexs;//边int[][] edges;//初始化public Graph(int size) {this.size=size;this.vertexs=new ArrayList<Node>(size);this.edges=new int[size][size];}//添加顶点public void addVertex(Node node) {node.setIndex(index);vertexs.add(node);index++;}//添加边:有权重有方向public void addEdge(Node vertex1,Node vertex2,int weight) {//因为是无向图,所以这里直接把两条边都加上edges[vertex1.getIndex()][vertex2.getIndex()]=weight;edges[vertex2.getIndex()][vertex1.getIndex()]=weight;}public List<Node> getVertexs() {return vertexs;}/***************上面已经做好了图,现在做遍历********************//*** 打印图* @param index*/public void printGraph() {System.out.print("图\t ");for (Node vertex: vertexs) {System.out.print(vertex.getValue()+"\t");}System.out.println("\n");for (int i = 0; i <size; i++) {Node vertex = vertexs.get(i);System.out.print(vertex.getValue()+"\t");for (int j = 0; j < size; j++) {System.out.print(edges[i][j]+"\t");}System.out.println("\n");}System.out.println();}/*** 获取节点index相邻的节点* @param index* @return*/public List<Node> getAdjacentVertexIndex(Node node) {List<Node> lists = new ArrayList<Node>();for (int j = 0; j < size; j++) {if(edges[node.getIndex()][j]!=0) {lists.add(vertexs.get(j));}}return lists;}}
上面都准备好了后,我们就可以根据伪代码中的逻辑来实现最小生成树啦!
public static List<Node> prim(Graph graph){//1、初始化一个最小优先队列PriorityQueue<Node> Q = new PriorityQueue<Node>();//这里第一个顶点的key是0,其他都是Integer.MAX_VALUE 代表无穷List<Node> nodes = graph.getVertexs();for (int i = 0; i < nodes.size(); i++) {Node node = nodes.get(i);node.setParent(null);if(i==0) {node.setKey(0);}else {node.setKey(Integer.MAX_VALUE);}Q.add(node);}//2、初始化生成树A,一开始树A为空,全部节点都还在Q中List<Node> A = new ArrayList<Node>();/*** 上面初始化最小堆的时间复杂度为O(V)*///3、开始执行逻辑while(Q.getSize()!=0) {//这个要执行|V|次//4、获取第一个节点Node minNode = Q.extractMin();//这一步的时间复杂度是:O(VlgV)//5、取出这个节点对应的连接边List<Node> adjNodes = graph.getAdjacentVertexIndex(minNode);for (int i = 0; i < adjNodes.size(); i++) {//这里要执行|E|次//6、检查该节点是否属于集合QNode node = adjNodes.get(i);/*** 对每个节点维护一个标志位来指明该节点是否属于Q,* 并在将节点Q从Q中移除的时候将标志位进行更新,时间复杂度则为O(1)*/if(node.getInQ()==1) {//7、获取这个邻接边的权重int weight = graph.edges[minNode.getIndex()][node.getIndex()];if(weight<node.getKey()) {//8、更新node的值node.setParent(minNode);//这一行操作涉及后面需要重新建堆node.setKey(weight);//重新建堆Q.rebuildHead(node);//这一步的时间复杂度是O(ElgV)}}}//10,将该节点加入集合AminNode.setInQ(0);A.add(minNode);}//所以时间复杂度为O(V+VlgV+ElgV)=O(ElgV)=O(ElgV)return A;}
好了,到这里就已经实现完了,把代码整合测试下:
Java实现Prim算法
/*** 连通无向图最小生成树Prim算法Java实现* @author suibibk@qq.com*/public class Prim {public static List<Node> prim(Graph graph){//1、初始化一个最小优先队列PriorityQueue<Node> Q = new PriorityQueue<Node>();//这里第一个顶点的key是0,其他都是Integer.MAX_VALUE 代表无穷List<Node> nodes = graph.getVertexs();for (int i = 0; i < nodes.size(); i++) {Node node = nodes.get(i);node.setParent(null);if(i==0) {node.setKey(0);}else {node.setKey(Integer.MAX_VALUE);}Q.add(node);}//2、初始化生成树A,一开始树A为空,全部节点都还在Q中List<Node> A = new ArrayList<Node>();/*** 上面初始化最小堆的时间复杂度为O(V)*///3、开始执行逻辑while(Q.getSize()!=0) {//这个要执行|V|次//4、获取第一个节点Node minNode = Q.extractMin();//这一步的时间复杂度是:O(VlgV)//5、取出这个节点对应的连接边List<Node> adjNodes = graph.getAdjacentVertexIndex(minNode);for (int i = 0; i < adjNodes.size(); i++) {//这里要执行|E|次//6、检查该节点是否属于集合QNode node = adjNodes.get(i);/*** 对每个节点维护一个标志位来指明该节点是否属于Q,* 并在将节点Q从Q中移除的时候将标志位进行更新,时间复杂度则为O(1)*/if(node.getInQ()==1) {//7、获取这个邻接边的权重int weight = graph.edges[minNode.getIndex()][node.getIndex()];if(weight<node.getKey()) {//8、更新node的值node.setParent(minNode);//这一行操作涉及后面需要重新建堆node.setKey(weight);//重新建堆Q.rebuildHead(node);//这一步的时间复杂度是O(ElgV)}}}//10,将该节点加入集合AminNode.setInQ(0);A.add(minNode);}//所以时间复杂度为O(V+VlgV+ElgV)=O(ElgV)=O(ElgV)return A;}/*** 打印最小生成树的节点A* @param graph 图 作用是找到节点名称* @param A*/public static void printPrim(List<Node> A) {//这里就已经生成了最小生成树了,遍历输出Afor (int i = 0; i < A.size(); i++) {Node node = A.get(i);String vertex = node.getValue();Node parent = node.getParent();String pVertex = "NIL";if(parent!=null) {pVertex=parent.getValue();}System.out.println("节点:"+vertex+";父节点:"+pVertex+";权重:"+node.getKey());}}public static Graph getGraph() {Graph graph = new Graph(6);Node A = new Node("A");Node B = new Node("B");Node C = new Node("C");Node D = new Node("D");Node E = new Node("E");Node F = new Node("F");graph.addVertex(A);graph.addVertex(B);graph.addVertex(C);graph.addVertex(D);graph.addVertex(E);graph.addVertex(F);graph.addEdge(A, B,6);graph.addEdge(A, D,5);graph.addEdge(A, C,1);graph.addEdge(B, C,5);graph.addEdge(C, D,5);graph.addEdge(B, E,3);graph.addEdge(D, F,2);graph.addEdge(C, F,4);graph.addEdge(E, F,6);graph.addEdge(E, C,6);return graph;}public static void main(String[] args) {//获取一个图Graph graph = getGraph();graph.printGraph();//获取该图的最小生成树List<Node> A = prim(graph);printPrim(A);}}//图的节点,当然也是最小优先队列Q的节点,也是最小生成树A的节点:因此多了属性key,parent,inQclass Node implements Comparable<Node>{private int index;//坐标private int key;//每个节点的key属性private String value;//节点名称private Node parent;//父节点private int inQ=1;//是否属于Q,默认是属于的,等离开才不属于@Overridepublic int compareTo(Node o) {return this.key-o.key;}public Node(String value) {super();this.value = value;}public int getIndex() {return index;}public void setIndex(int index) {this.index = index;}public int getKey() {return key;}public void setKey(int key) {this.key = key;}public String getValue() {return value;}public void setValue(String value) {this.value = value;}public Node getParent() {return parent;}public void setParent(Node parent) {this.parent = parent;}public int getInQ() {return inQ;}public void setInQ(int inQ) {this.inQ = inQ;}}//定义图:无向图class Graph{//顶点数目int size;int index=0;//顶点private List<Node> vertexs;//边int[][] edges;//初始化public Graph(int size) {this.size=size;this.vertexs=new ArrayList<Node>(size);this.edges=new int[size][size];}//添加顶点public void addVertex(Node node) {node.setIndex(index);vertexs.add(node);index++;}//添加边:有权重有方向public void addEdge(Node vertex1,Node vertex2,int weight) {//因为是无向图,所以这里直接把两条边都加上edges[vertex1.getIndex()][vertex2.getIndex()]=weight;edges[vertex2.getIndex()][vertex1.getIndex()]=weight;}public List<Node> getVertexs() {return vertexs;}/***************上面已经做好了图,现在做遍历********************//*** 打印图* @param index*/public void printGraph() {System.out.print("图\t ");for (Node vertex: vertexs) {System.out.print(vertex.getValue()+"\t");}System.out.println("\n");for (int i = 0; i <size; i++) {Node vertex = vertexs.get(i);System.out.print(vertex.getValue()+"\t");for (int j = 0; j < size; j++) {System.out.print(edges[i][j]+"\t");}System.out.println("\n");}System.out.println();}/*** 获取节点index相邻的节点* @param index* @return*/public List<Node> getAdjacentVertexIndex(Node node) {List<Node> lists = new ArrayList<Node>();for (int j = 0; j < size; j++) {if(edges[node.getIndex()][j]!=0) {lists.add(vertexs.get(j));}}return lists;}}/***最小堆实现的一个优先队列* @author suibibk@qq.com*/class PriorityQueue<E extends Comparable<E>> {//这里使用数组来实现private ArrayList<E> data;public PriorityQueue(int capacity) {data = new ArrayList<>(capacity);}public PriorityQueue() {data = new ArrayList<>();}//返回堆中元素的个数public int getSize() {return data.size();}//返回二叉树中索引为index的节点的父节点索引public int parent(int index) {if(index == 0) {throw new IllegalArgumentException("index-0 dosen't have parent");}return (index-1)/2;}//返回完全二叉树中索引为index的节点的左孩子的索引private int leftChild(int index) {return index*2+1;}//返回完全二叉树中索引为index的节点的右孩子的索引private int rightChild(int index) {return index * 2 + 2;}//交换索引为i、j的值private void swap(int i, int j) {E t = data.get(i);data.set(i, data.get(j));data.set(j, t);}//向堆中添加元素public void add(E e) {data.add(e);siftUp(data.size() - 1);}//上浮private void siftUp(int k) {//k不能是根节点,并且k的值要比父节点的值小while (k > 0 && data.get(parent(k)).compareTo(data.get(k)) > 0) {swap(k, parent(k));k = parent(k);}}//看堆中最小的元素public E findMin() {if (data.size() == 0)throw new IllegalArgumentException("Can not findMax when heap is empty");return data.get(0);}//取出堆中最小的元素public E extractMin() {E ret = findMin();swap(0, data.size() - 1);data.remove(data.size() - 1);siftDown(0);return ret;}/*** 当修改了堆中一些元素后,要执行先向下浮再向上浮的操作,这里需要重新建堆*/public void rebuildHead(E e) {// 这里优化为在建优先队列的时候,就指定节点在优先队列中的坐标,那么就不需要使用循环for (int j = 0; j < data.size(); j++) {if(e==data.get(j)) {siftDown(j);siftUp(j);break;}}}//下浮private void siftDown(int k) {//leftChild存在while (leftChild(k) < data.size()) {int j = leftChild(k);//rightChild存在,且值小于leftChild的值if (j + 1 < data.size() &&data.get(j).compareTo(data.get(j + 1)) > 0)j = rightChild(k);//data[j]是leftChild和rightChild中最小的if (data.get(k).compareTo(data.get(j)) <0)break;swap(k, j);k = j;}}//取出堆中最大的元素,替换为元素epublic E replace(E e){E ret = findMin();data.set(0, e);siftDown(0);return ret;}//heapify操作:将数组转化为堆public PriorityQueue(E[] arrs) {data = new ArrayList<>(Arrays.asList(arrs));for (int i = parent(data.size() - 1); i >= 0; i--) {siftDown(i);}}public void print() {for (E e : data) {System.out.print(" "+e);}}public List<E> getDate() {return data;}}
输入上面的图,运行结果如下:
图 A B C D E FA 0 6 1 5 0 0B 6 0 5 0 3 0C 1 5 0 5 6 4D 5 0 5 0 0 2E 0 3 6 0 0 6F 0 0 4 2 6 0节点:A;父节点:NIL;权重:0节点:C;父节点:A;权重:1节点:F;父节点:C;权重:4节点:D;父节点:F;权重:2节点:B;父节点:C;权重:5节点:E;父节点:B;权重:3
可以看到结果跟伪代码执行逻辑结果是一样的,大功搞成!要了老命,这篇笔记写了6个钟!
