1. 向量表征(Vector Representation)
在人工智能领域,向量表征(Vector Representation)是核心概念之一。通过将文本、图像、声音、行为甚至复杂关系转化为高维向量(Embedding),AI系统能够以数学方式理解和处理现实世界中的复杂信息。这种表征方式为机器学习模型提供了统一的“语言”。
1.1. 向量表征的本质
向量表征的本质:万物皆可数学化
(1)核心思想
降维抽象:将复杂对象(如一段文字、一张图片)映射到低维稠密向量空间,保留关键语义或特征。
相似性度量:向量空间中的距离(如余弦相似度)反映对象之间的语义关联(如“猫”和“狗”的向量距离小于“猫”和“汽车”)。
(2)数学意义
特征工程自动化:传统机器学习依赖人工设计特征(如文本的TF-IDF),而向量表征通过深度学习自动提取高阶抽象特征。
跨模态统一:文本、图像、视频等不同模态数据可映射到同一向量空间,实现跨模态检索(如“用文字搜图片”)。
1.2. 向量表征的典型应用场景
(1)自然语言处理(NLP)
词向量(Word2Vec、GloVe):单词映射为向量,解决“一词多义”问题(如“苹果”在“水果”和“公司”上下文中的不同向量)。
句向量(BERT、Sentence-BERT):整句语义编码,用于文本相似度计算、聚类(如客服问答匹配)。
知识图谱嵌入(TransE、RotatE):将实体和关系表示为向量,支持推理(如预测“巴黎-首都-法国”的三元组可信度)。
(2)计算机视觉(CV)
图像特征向量(CNN特征):ResNet、ViT等模型提取图像语义,用于以图搜图、图像分类。
跨模态对齐(CLIP):将图像和文本映射到同一空间,实现“描述文字生成图片”或反向搜索。
(3)推荐系统
- 用户/物品向量:用户行为序列(点击、购买)编码为用户向量,商品属性编码为物品向量,通过向量内积预测兴趣匹配度(如YouTube推荐算法)。
(4)复杂系统建模
图神经网络(GNN):社交网络中的用户、商品、交互事件均表示为向量,捕捉网络结构信息(如社区发现、欺诈检测)。
时间序列向量化:将股票价格、传感器数据编码为向量,预测未来趋势(如LSTM、Transformer编码)。
1.3. 向量表征的技术实现
(1)经典方法
无监督学习:Word2Vec通过上下文预测(Skip-Gram)或矩阵分解(GloVe)生成词向量。
有监督学习:微调预训练模型(如BERT)适应具体任务,提取任务相关向量。
(2)前沿方向
对比学习(Contrastive Learning):通过构造正负样本对(如“同一图片的不同裁剪”为正样本),拉近正样本向量距离,推开负样本(SimCLR、MoCo)。
多模态融合:将文本、图像、语音等多模态信息融合为统一向量(如Google的MUM模型)。
动态向量:根据上下文动态调整向量(如Transformer的注意力机制),解决静态词向量无法适应多义性的问题
2. 什么是向量
向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。
1 文本向量(Text Embeddings)
- 将文本转成一组 N 维浮点数,即文本向量又叫 Embeddings
- 向量之间可以计算距离,距离远近对应语义相似度大小
2.2. 文本向量是怎么得到的
- 构建相关(正例)与不相关(负例)的句子对样本
- 训练双塔式模型,让正例间的距离小,负例间的距离大
2.3 向量间的相似度计算
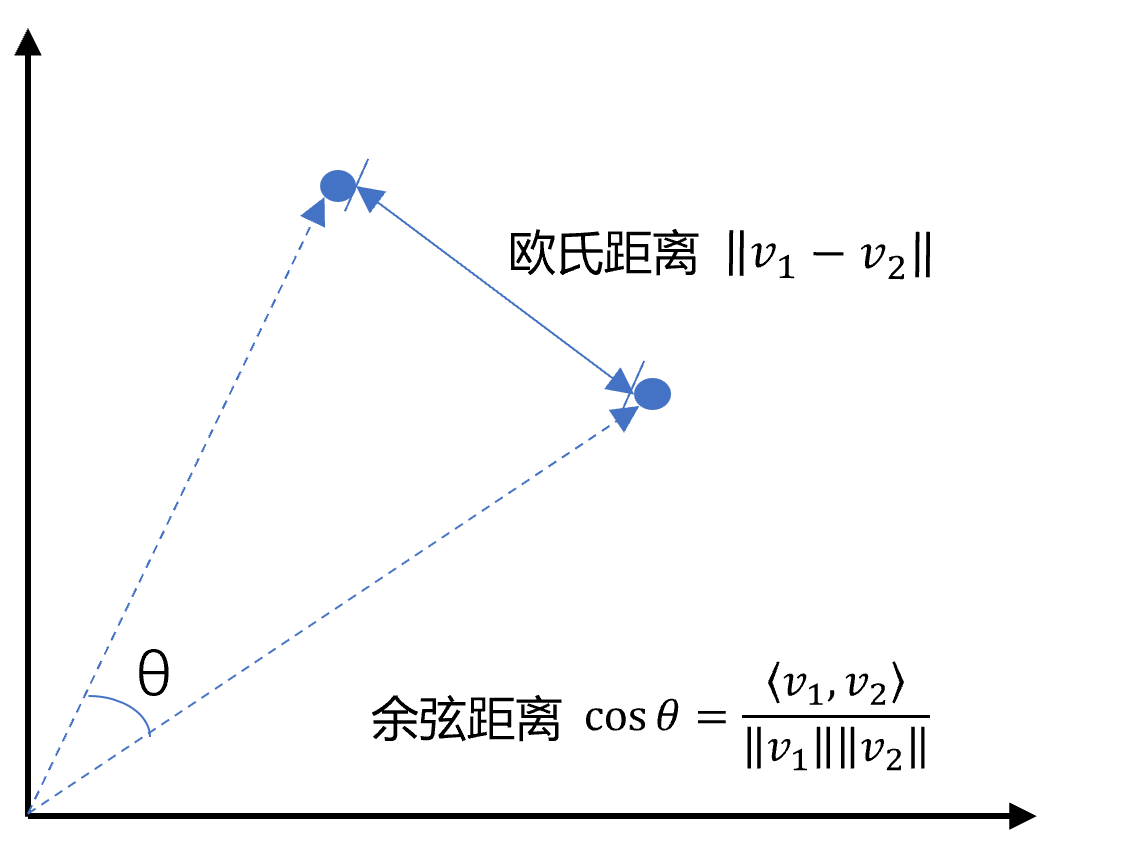
余弦相似度是通过计算两个向量夹角的余弦值来衡量相似性,等于两个向量的点积除以两个向量长度的乘积。
3、 Embedding Models 嵌入模型
3.1. 什么是嵌入(Embedding)?
嵌入(Embedding)是指非结构化数据转换为向量的过程,通过神经网络模型或相关大模型,将真实世界的离散数据投影到高维数据空间上,根据数据在空间中的不同距离,反映数据在物理世界的相似度。
3.2. 嵌入模型概念及原理
3.1. 嵌入模型的本质
嵌入模型(Embedding Model)是一种将离散数据(如文本、图像)映射到连续向量空间的技术。通过高维向量表示(如 768 维或 3072 维),模型可捕捉数据的语义信息,使得语义相似的文本在向量空间
中距离更近。例如,“忘记密码”和“账号锁定”会被编码为相近的向量,从而支持语义检索而非仅关键词匹配。
2. 核心作用
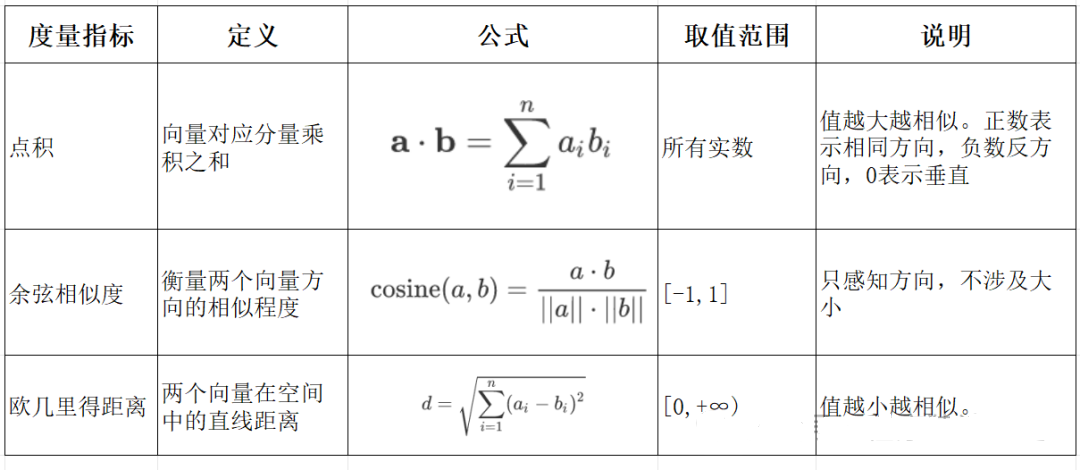
语义编码:将文本、图像等转换为向量,保留上下文信息(如 BERT 的 CLS Token 或均值池化。相似度计算:通过余弦相似度、欧氏距离等度量向量关联性,支撑检索增强生成(RAG)、推荐系统等应用。
信息降维:压缩复杂数据为低维稠密向量,提升存储与计算效率。
3. 关键技术原理
上下文依赖:现代模型(如 BGE-M3)动态调整向量,捕捉多义词在不同语境中的含义。
训练方法:对比学习(如 Word2Vec 的 Skip-gram/CBOW)、预训练+微调(如 BERT)。
3.3. 主流嵌入模型分类与选型指南
Embedding 模型将文本转换为数值向量,捕捉语义信息,使计算机能够理解和比较内容的”意义”。选择 Embedding 模型的考虑因素:
| 因素 | 说明 |
|---|---|
| 任务性质 | 匹配任务需求(问答、搜索、聚类等) |
| 领域特性 | 通用vs专业领域(医学、法律等) |
| 多语言支持 | 需处理多语言内容时考虑 |
| 维度 | 权衡信息丰富度与计算成本 |
| 许可条款 | 开源vs专有服务 |
| 最大Tokens | 适合的上下文窗口大小 |
最佳实践:为特定应用测试多个 Embedding 模型,评估在实际数据上的性能而非仅依赖通用基准。
1. 通用全能型
- BGE-M3:北京智源研究院开发,支持多语言、混合检索(稠密+稀疏向量),处理 8K 上下文,适合企业级知识库。
- NV-Embed-v2:基于 Mistral-7B,检索精度高(MTEB 得分 62.65),但需较高计算资源。
2. 垂直领域特化型
- 中文场景: BGE-large-zh-v1.5 (合同/政策文件)、 M3E-base (社交媒体分析)。
- 多模态场景: BGE-VL (图文跨模态检索),联合编码 OCR 文本与图像特征。
3. 轻量化部署型
- nomic-embed-text:768 维向量,推理速度比 OpenAI 快 3 倍,适合边缘设备。
- gte-qwen2-1.5b-instruct:1.5B 参数,16GB 显存即可运行,适合初创团队原型验。
选型决策树:
中文为主 → BGE 系列 > M3E;
多语言需求 → BGE-M3 > multilingual-e5;
预算有限 → 开源模型(如 Nomic Embed)
Embddding Leaderboard
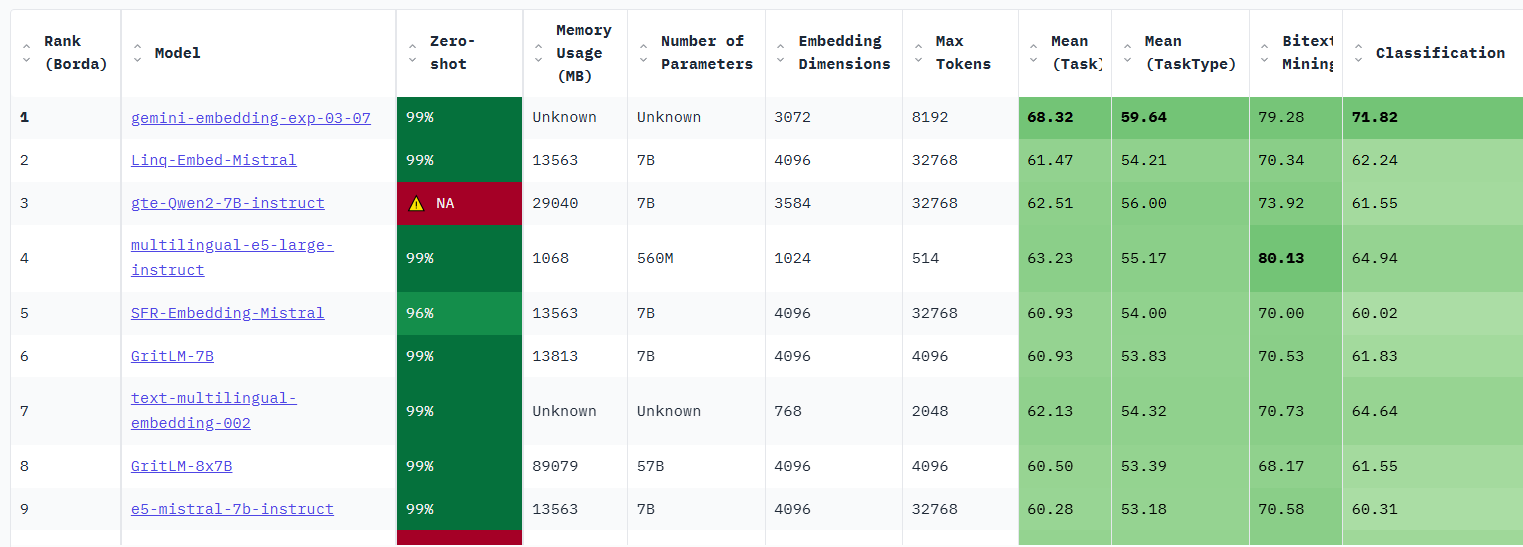
https://huggingface.co/spaces/mteb/leaderboard
3.5. 嵌入模型使用
我们这里使用嵌入模型,使用的是各大厂商提供的,比如这里用阿里百炼举例子
1.先去官网注册,然后申请key
https://bailian.console.aliyun.com/
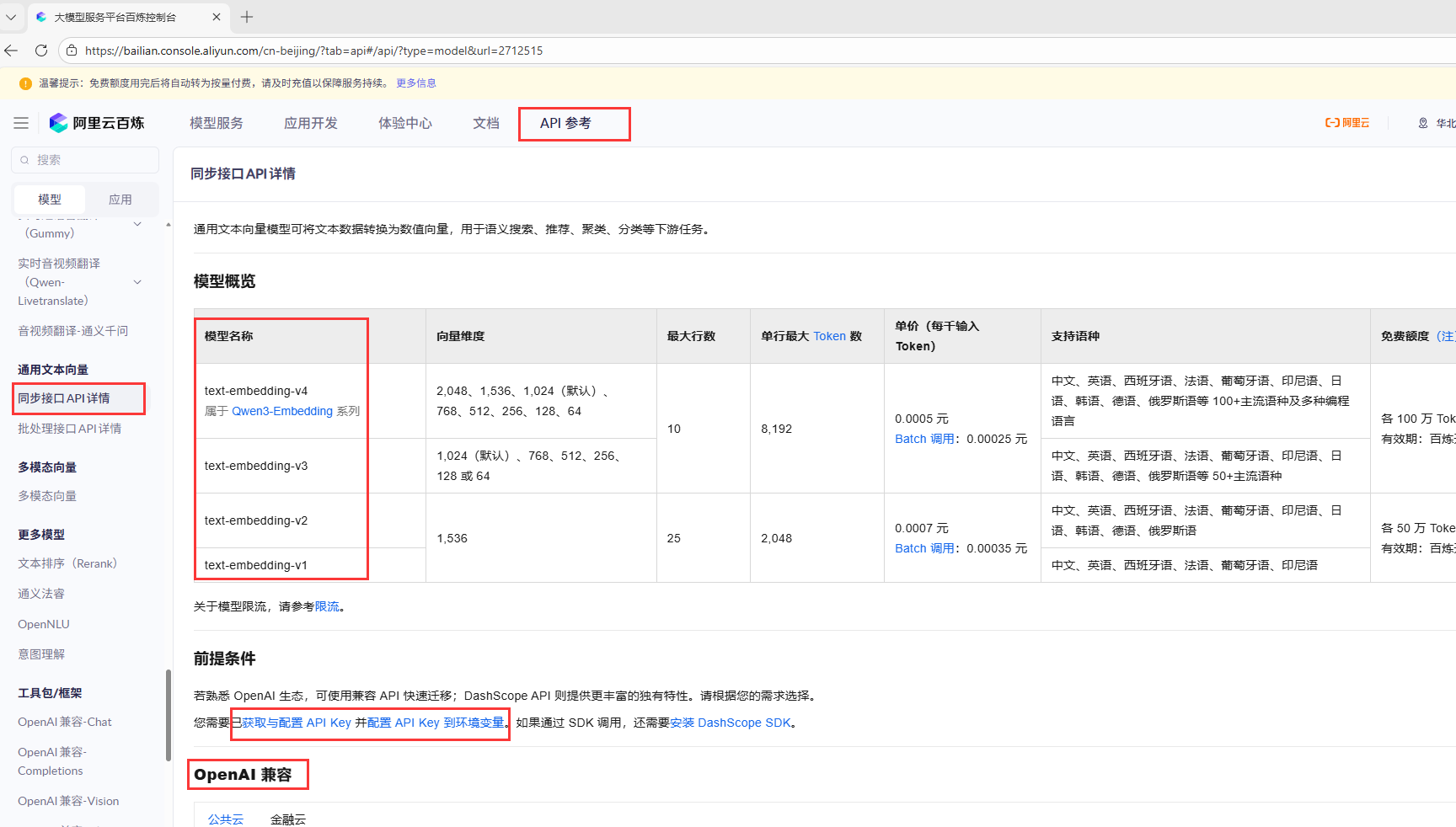
跟着官网找到通用文本向量。文档下面就有API的调用方式。我们申请好key和配置好环境变量后,就可以用代码进行调用了,这里用的是python.
2.调用API
安装openai
pip install openai
执行下面的代码
import osfrom openai import OpenAIdef study01():client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url)completion = client.embeddings.create(model="text-embedding-v4",input=['衣服的质量杠杠的,很漂亮,不枉我等了这么久啊,喜欢,以后还来这里买','小猫爱吃糖果'],dimensions=1024, # 指定向量维度(仅 text-embedding-v3及 text-embedding-v4支持该参数)encoding_format="float")print(completion.model_dump_json())# 程序入口:只有直接运行这个文件时,才执行游戏if __name__ == "__main__":study01()
将会打印如下内容
可以看到,模型把我们的两句话或者说两个text转成了两个维度为1024维的向量。
注:api的调用是需要消耗token的,但是阿里给的免费额度根本用不完。
3.比较两个向量的相似度
这里我们用的是上面提过的余弦和欧拉距离来举例,为什么余弦能够比较相似的,这个应该很好理解,两个向量的余弦夹角越小,余弦值越大,越接近,应该是比较直观的,这里要用到numpy库,所以需要先安装这个库。
pip install numpy
下面是代码例子
#核心是和系统交互,重点用于安全读取 API 密钥import os#对接大模型 API,核心是获取文本的向量表示;from openai import OpenAI#基础数值计算库,核心是存储和处理向量数组;import numpy as np#计算向量点积,是余弦相似度的分子部分;from numpy import dot#计算向量模长,是余弦相似度的分母部分。from numpy.linalg import norm#获取客户端client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url)def cos_sim(a,b):'''计算两个向量的余弦距离,余弦越大越相似'''return dot(a,b)/(norm(a)*norm(b))def l2(a,b):'''欧氏距离,值越小越相似'''#逐元素减法,最后得到一个新的数组x = np.asarray(a)-np.asarray(b)#计算向量模长return norm(x)def get_embeddings(texts,model = "text-embedding-v4",dimensions=1024):data = client.embeddings.create(input=texts,model=model,dimensions=dimensions).datareturn [x.embedding for x in data]def study02():test_query = ["奶奶买了两只鸡,大公鸡和大母鸡","一只会下蛋,一只清早喔喔叫"]#获取向量vec = get_embeddings(test_query)[0]#获取向量维度print(f"Total dimension:{len(vec)}")#获取前十个元素print(f"First 10 elements:{vec[:10]}")#相似度计算测试def study03():query = "Java是世界上最棒的语言";#下面是一些类似的文本documents = ["springboot也不错的,很方便,很容易就能搭建一个好的框架","PHP也是很棒的,但是这个语言现在用的比较少了","python也是牛逼啊,写这个代码用的就是python","JVM虚拟机可以让Java跨平台运行,棒棒的"]#先获取查询文本的向量,只有一段,所以取第一行就行了query_vec = get_embeddings(query)[0]#获取数组文本的向量doc_vecs = get_embeddings(documents)#判断下自己与自己的余弦距离,理论上应该是1,毕竟余弦越大,向量夹角越小越相似print("Query与自己的余弦距离:{:.2f}".format(cos_sim(query_vec,query_vec)))print("Query与Documents的余弦距离")for vec in doc_vecs:print(cos_sim(query_vec,vec))print()#判断下自己与自己的欧式距离,理论上应该是0,毕竟越小,越相似print("Query与自己的欧式距离:{:.2f}".format(l2(query_vec,query_vec)))print("Query与Documents的欧式距离")for vec in doc_vecs:print(l2(query_vec,vec))'''Query与自己的余弦距离:1.00Query与Documents的余弦距离0.46337653920781140.5641196199814890.415554686063183630.6286688534363498Query与自己的欧式距离:0.00Query与Documents的欧式距离1.03597631254136370.93368120902525681.08115239867133830.8617785296079025'''# 程序入口:只有直接运行这个文件时,才执行游戏if __name__ == "__main__":#study02()study03()
4. 向量数据库
4.1. 什么是向量数据库?
向量数据库,是专门为向量检索设计的中间件!
高效存储、快速检索和管理高纬度向量数据的系统称为向量数据库
一种专门用于存储和检索高维向量数据的数据库。它将数据(如文本、图像、音频等)通过嵌入模型转换为向量形式,并通过高效的索引和搜索算法实现快速检索。
向量数据库的核心作用是实现相似性搜索,即通过计算向量之间的距离(如欧几里得距离、余弦相似度等)来找到与目标向量最相似的其他向量。它特别适合处理非结构化数据,支持语义搜索、内容推荐等场景。
核心功能:
向量存储
相似性度量
相似性搜索
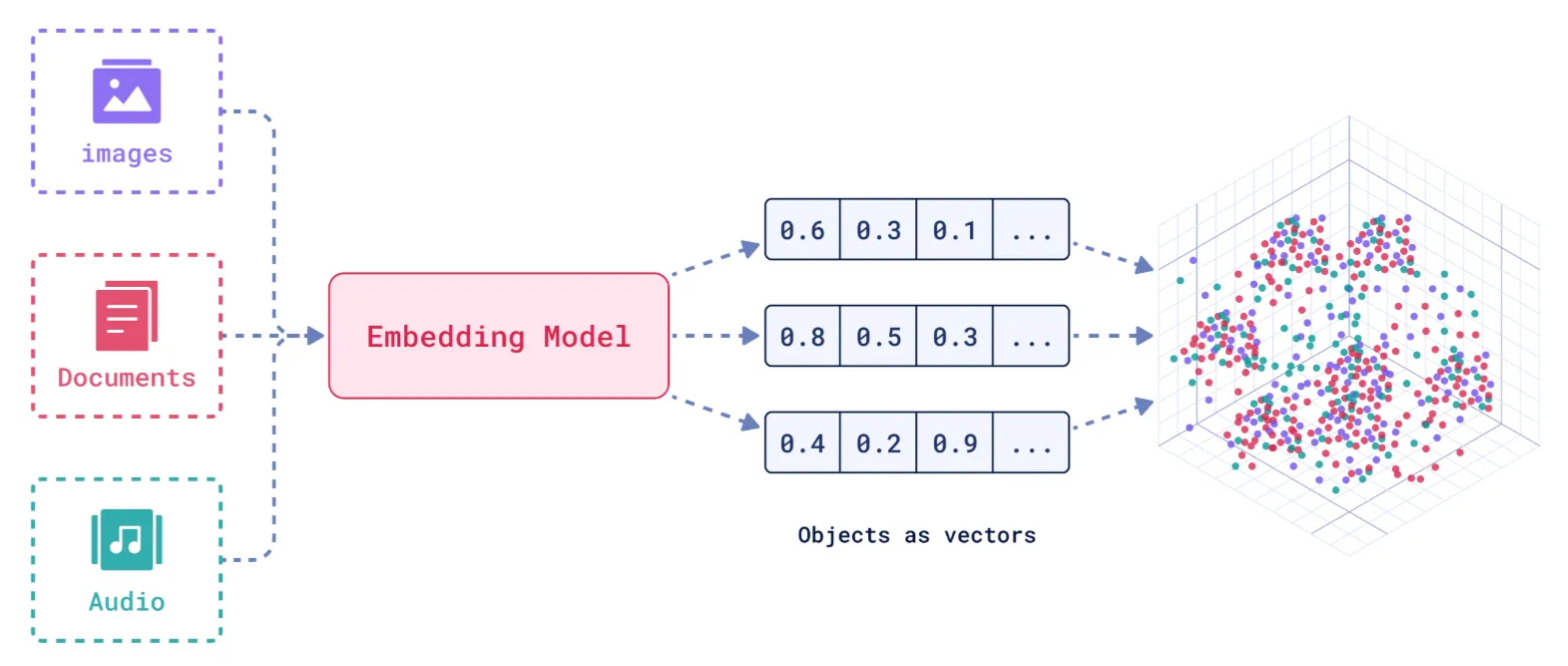
4.2. 如何存储和检索嵌入向量?
存储:向量数据库将嵌入向量存储为高维空间中的点,并为每个向量分配唯一标识符(ID),同时支持存储元数据。
检索:通过近似最近邻(ANN)算法(如PQ等)对向量进行索引和快速搜索。比如,FAISS和Milvus等数据库通过高效的索引结构加速检索。
4.3 向量数据库与传统数据库对比
- 数据类型
- 传统数据库:存储结构化数据(如表格、行、列)。
- 向量数据库:存储高维向量数据,适合非结构化数据。
- 查询方式
- 传统数据库:依赖精确匹配(如=、<、>)。
- 向量数据库:基于相似度或距离度量(如欧几里得距离、余弦相似度)。
- 应用场景
- 传统数据库:适合事务记录和结构化信息管理。
- 向量数据库:适合语义搜索、内容推荐等需要相似性计算的场景。
澄清几个关键概念:
- 向量数据库的意义是快速的检索;
- 向量数据库本身不生成向量,向量是由 Embedding 模型产生的;
- 向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
4.4. 主流向量数据库功能对比
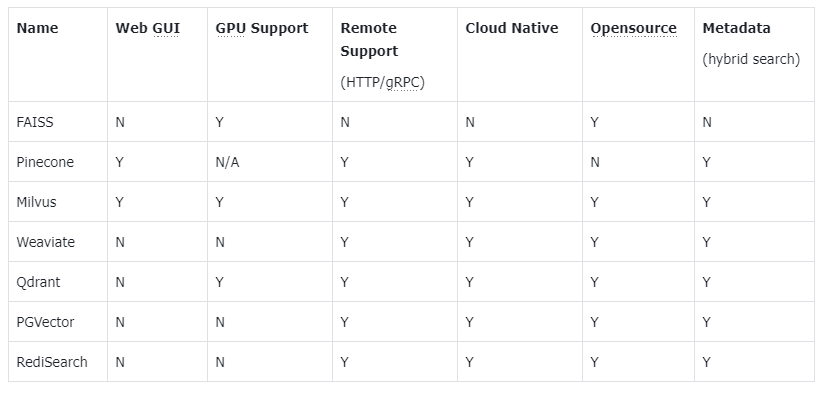
- FAISS: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss
- Pinecone: 商用向量数据库,只有云服务 https://www.pinecone.io/
- Milvus: 开源向量数据库,同时有云服务 https://milvus.io/
- Weaviate: 开源向量数据库,同时有云服务 https://weaviate.io/
- Qdrant: 开源向量数据库,同时有云服务 https://qdrant.tech/
- PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector
- RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch
- ElasticSearch 也支持向量检索 https://www.elastic.co/enterprise-search/vector-search
4.5. Chroma 向量数据库
官方文档:https://docs.trychroma.com/docs/overview/introduction
1. 什么是 Chroma?
Chroma 是一款开源的向量数据库,专为高效存储和检索高维向量数据设计。其核心能力在于语义相似性搜索,支持文本、图像等嵌入向量的快速匹配,广泛应用于大模型上下文增强(RAG)、推荐系统、多模态检索等场景。与传统数据库不同,Chroma 基于向量距离(如余弦相似度、欧氏距离)衡量数据关联性,而非关键词匹配。
2. 核心优势
- 轻量易用:以 Python/JS 包形式嵌入代码,无需独立部署,适合快速原型开发。
- 灵活集成:支持自定义嵌入模型(如 OpenAI、HuggingFace),兼容 LangChain 等框架。
- 高性能检索:采用 HNSW 算法优化索引,支持百万级向量毫秒级响应。
- 多模式存储:内存模式用于开发调试,持久化模式支持生产环境数据落地。
4.6. Chroma 安装与基础配置
1. 安装
通过 Python 包管理器安装 ChromaDB:
pip install chromadb
2. 初始化客户端
- 内存模式(一般不建议使用)数据重启会丢失:
import chromadb# 1. 初始化内存客户端(默认模式)client = chromadb.Client() # 等价于 chromadb.EphemeralClient()
1. 集合(Collection)
集合是 Chroma 中管理数据的基本单元,类似关系数据库的表:
(1)创建集合
import osimport chromadbfrom chromadb.utils import embedding_functionsfrom chromadb import Documents, EmbeddingFunction, Embeddingsfrom openai import OpenAI# 默认情况下,Chroma 使用 DefaultEmbeddingFunction,它是基于 Sentence Transformers 的 MiniLM-L6-v2 模型default_ef = embedding_functions.DefaultEmbeddingFunction()# ---------------------- 1. 自定义百炼嵌入函数 ----------------------class DashScopeEmbeddingFunction(EmbeddingFunction):"""自定义嵌入函数,调用阿里百炼的文本嵌入模型"""def __init__(self):# 初始化OpenAI客户端(对接百炼兼容接口)self.client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")# 百炼嵌入模型名称(可根据需要替换)self.model_name = "text-embedding-v4"def __call__(self, texts: Documents) -> Embeddings:"""核心方法:接收文本列表,返回百炼生成的向量列表:param texts: 待嵌入的文本列表(Documents本质是List[str]):return: 向量列表(Embeddings本质是List[List[float]])"""try:# 调用百炼嵌入APIresponse = self.client.embeddings.create(model=self.model_name,input=texts, # 支持批量文本嵌入dimensions=1024)# 提取每个文本的向量(对应你之前问的列表推导式)embeddings = [x.embedding for x in response.data]return embeddingsexcept Exception as e:raise ValueError(f"调用百炼嵌入模型失败:{str(e)}")#数据保存到本地目录client = chromadb.PersistentClient(path="./chroma")# 2. 创建集合,指定自定义的百炼嵌入函数# 注意:集合创建时指定嵌入函数后,后续add/query会自动使用该函数collection = client.get_or_create_collection(name="my_collection",configuration = {# HNSW 索引算法,基于图的近似最近邻搜索算法(Approximate Nearest Neighbor,ANN)"hnsw": {"space": "cosine", # 指定余弦相似度计算"ef_search": 100,"ef_construction": 100,"max_neighbors": 16,"num_threads": 4},# 指定向量模型,也可以用默认的default_ef"embedding_function": DashScopeEmbeddingFunction #使用百炼模型DashScopeEmbeddingFunction})
如上,我们的嵌入模型可以用百炼的,也可以用默认的,若用默认的执行后若本地没有则会去下载
(2)查询集合
print(collection.peek())print(collection.count())
(3)删除集合
client.delete_collection(name="my_collection")
2. 添加数据
支持自动生成或手动指定嵌入向量:
# 3. 插入文本数据(自动调用百炼模型生成向量)collection.add(documents=["阿里云百炼是一站式大模型开发与服务平台","ChromaDB是轻量级的开源向量数据库","百炼支持多种大模型,包括通义千问、LLaMA等","向量数据库用于存储和检索大模型生成的嵌入向量"],#给文本添加 “补充说明”,方便后续检索时过滤数据(比如只检索来源是 “阿里云文档” 的内容);#提升检索结果的可读性(返回结果时可附带元数据,知道内容来源);metadatas=[{"source": "阿里云文档"},{"source": "ChromaDB官网"},{"source": "阿里云文档"},{"source": "技术博客"}],#唯一标记每条数据(类似数据库的主键 ID),确保集合中没有重复数据;#后续可通过 ids 精准查询 / 删除 / 更新指定数据(比如 collection.get(ids=["id1"]) 直接获取第一条数据);ids=["id1", "id2", "id3", "id4"])
当然实际使用过程中,我们一般都是先自己去调用模型获取向量,然后再加入
# 方式2:手动传入预计算向量(实际开发中推荐使用)collection.add(embeddings = get_embeddings("RAG是什么?")documents = ["文本1", "文本2"],ids = ["id3", "id4"])
3. 查询数据
- 文本查询(自动向量化):
#文本查询results = collection.query(query_texts=["向量数据库的作用?"],n_results=2)
- 向量查询(自定义输入):
#当然可以进行向量查询,这里我们可以自己缓存向量,然后查询,这样就不用每次都调用模型生成results = collection.query(query_embeddings = [[0.5, 0.6, ...]],n_results = 3)
4. 数据管理
更新集合中的数据:
collection.update(ids=["id1"], documents=["阿里云百炼是一站式大模型开发与服务平台,非常棒棒"])
删除集合中的数据:
collection.delete(ids=["id3"])
4.8. Chroma Client-Server Mode
- Server 端
默认端口 8000
chroma run --path /db_path
修改端口:—port 端口号
chroma run --port 8001 --path /db_path
# 远程连接 Chroma Serverclient = chromadb.HttpClient(host='localhost', port=8001)
这里面遇到报错,原来是因为我本地开启了代理。
5. Milvus 扩展学习
中文官网:https://milvus.io/zh
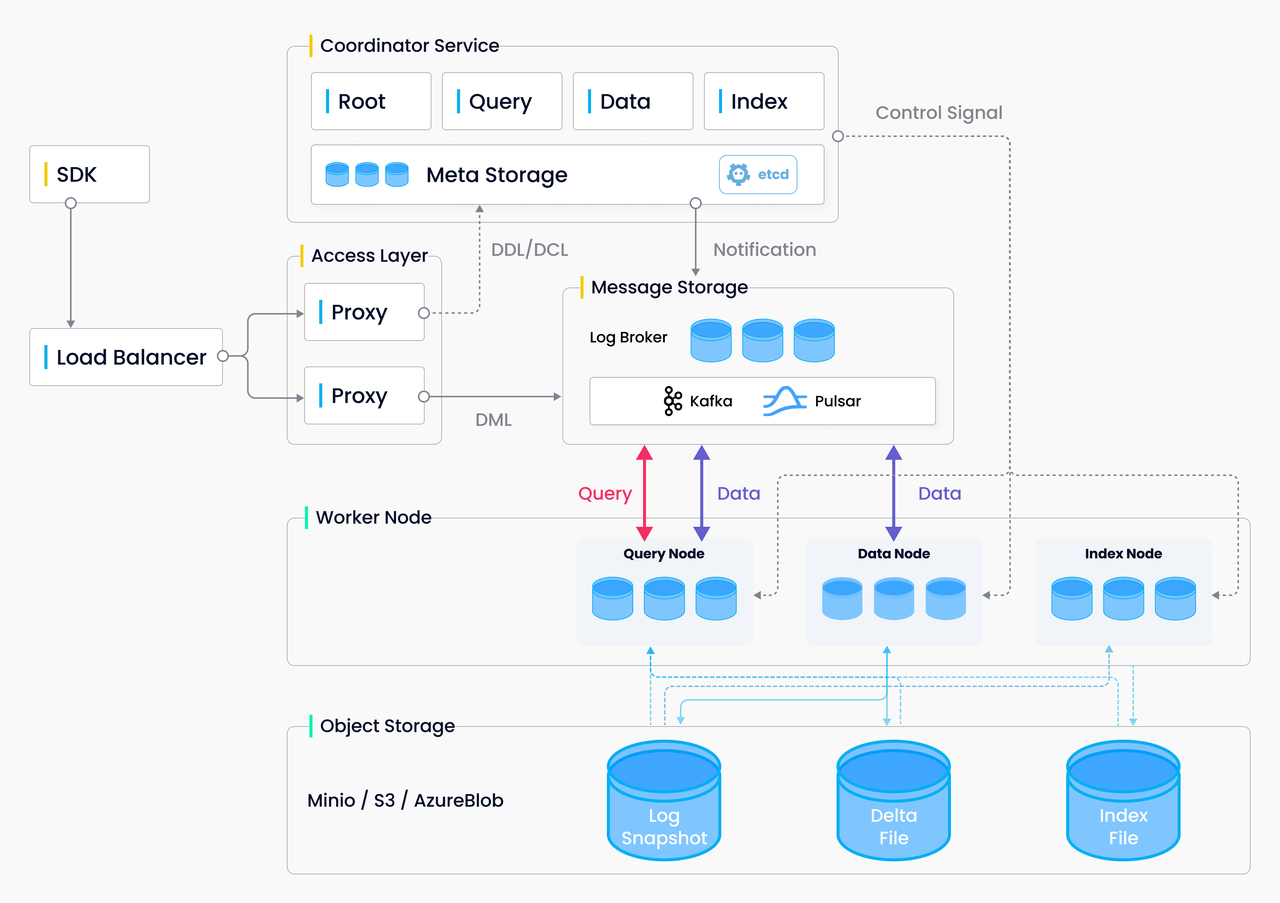
Milvus 架构图