





在目前主流的计算机中,cpu执行计算的主要流程如图所示:
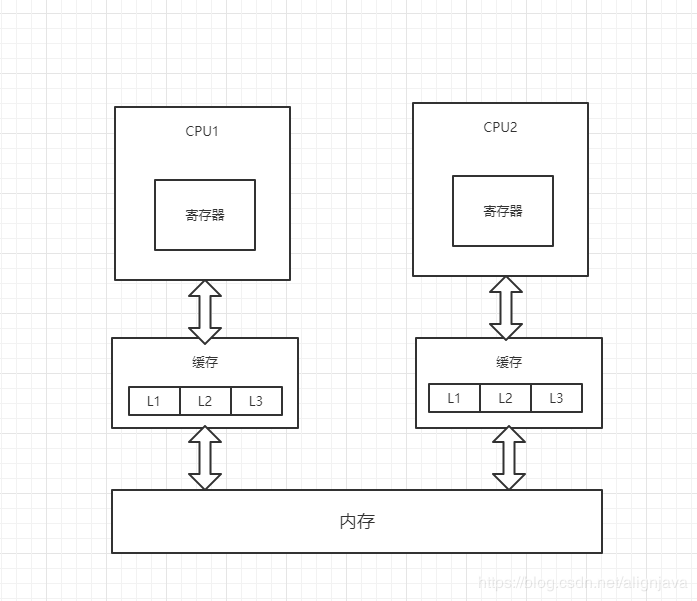
数据加载的流程如下:
1.将程序和数据从硬盘加载到内存中
2.将程序和数据从内存加载到缓存中(目前多三级缓存,数据加载顺序:L3->L2->L1)
3.CPU将缓存中的数据加载到寄存器中,并进行运算
4.CPU会将数据刷新回缓存,并在一定的时间周期之后刷新回内存
缓存一致性协议发展背景
现在的CPU基本都是多核CPU,服务器更是提供了多CPU的支持,而每个核心也都有自己独立的缓存,当多个核心同时操作多个线程对同一个数据进行更新时,如果核心2在核心1还未将更新的数据刷回内存之前读取了数据,并进行操作,就会造成程序的执行结果造成随机性的影响,这对于我们来说是无法容忍的。
而总线加锁是对整个内存进行加锁,在一个核心对一个数据进行修改的过程中,其他的核心也无法修改内存中的其他数据,这样对导致CPU处理性能严重下降。
缓存一致性协议提供了一种高效的内存数据管理方案,它只会对单个缓存行(缓存行是缓存中数据存储的基本单元)的数据进行加锁,不会影响到内存中其他数据的读写。
因此,我们引入了缓存一致性协议来对内存数据的读写进行管理。
MESI协议
缓存一致性协议有MSI,MESI,MOSI,Synapse,Firefly及DragonProtocol等等,接下来我们主要介绍MESI协议。
MESI分别代表缓存行数据所处的四种状态,通过对这四种状态的切换,来达到对缓存数据进行管理的目的。
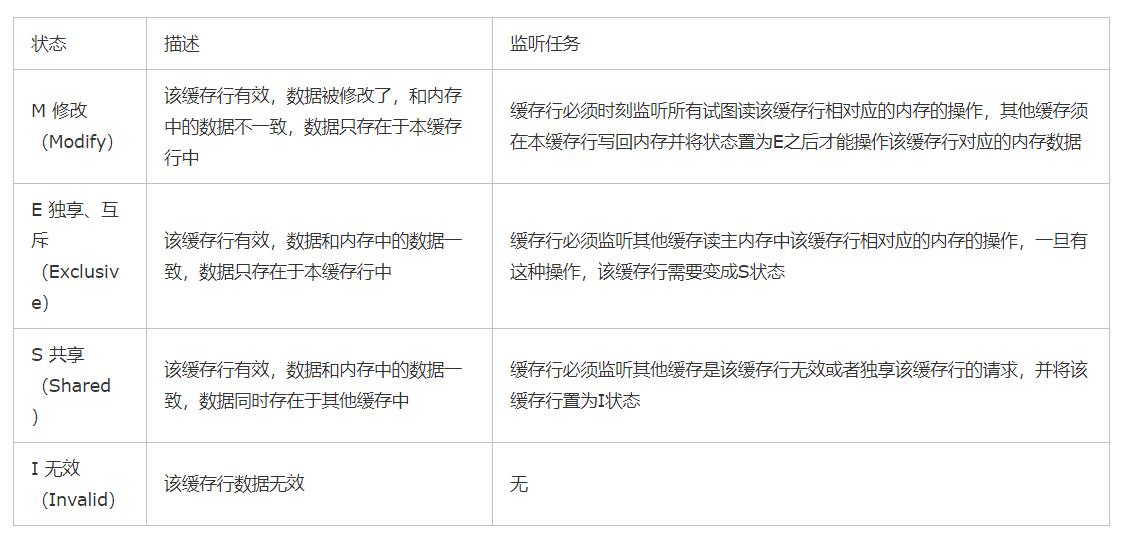
备注:
1.MESI协议只对汇编指令中执行加锁操作的变量有效,表现到java中为使用voliate关键字定义变量或使用加锁操作
2.对于汇编指令中执行加锁操作的变量,MESI协议在以下两种情况中也会失效:
一、CPU不支持缓存一致性协议。
二、该变量超过一个缓存行的大小(32bytes/64bytes/128bytes),缓存一致性协议是针对单个缓存行进行加锁,此时,缓存一致性协议无法再对该变量进行加锁,只能改用总线加锁的方式。二、该变量超过一个缓存行的大小(32bytes/64bytes/128bytes),缓存一致性协议是针对单个缓存行进行加锁,此时,缓存一致性协议无法再对该变量进行加锁,只能改用总线加锁的方式。
MESI工作原理
此处统一默认CPU为单核CPU,在多核CPU内部执行过程和一下流程一致
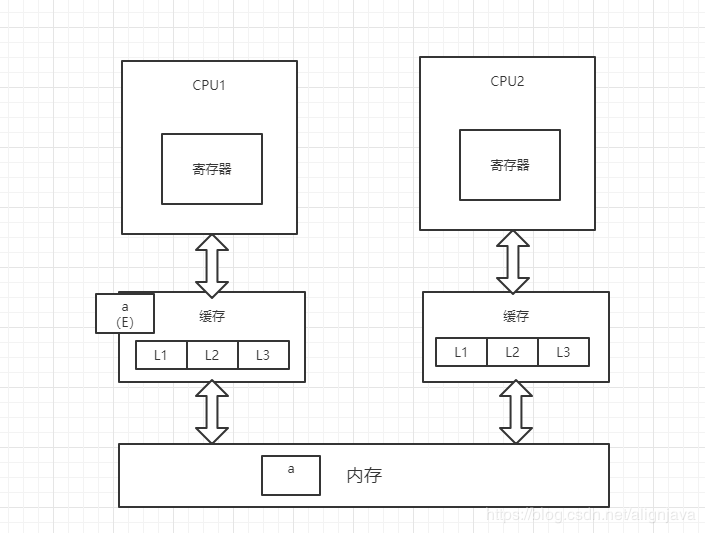
1、CPU1从内存中将变量a加载到缓存中,并将变量a的状态改为E(独享),并通过总线嗅探机制对内存中变量a的操作进行嗅探
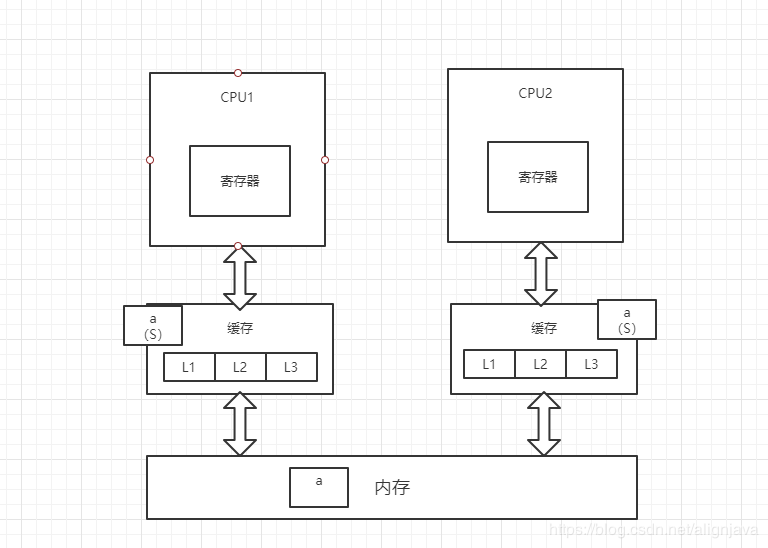
2、此时,CPU2读取变量a,总线嗅探机制会将CPU1中的变量a的状态置为S(共享),并将变量a加载到CPU2的缓存中,状态为S
3、CPU1对变量a进行修改操作,此时CPU1中的变量a会被置为M(修改)状态,而CPU2中的变量a会被通知,改为I(无效)状态,此时CPU2中的变量a做的任何修改都不会被写回内存中(高并发情况下可能出现两个CPU同时修改变量a,并同时向总线发出将各自的缓存行更改为M状态的情况,此时总线会采用相应的裁决机制进行裁决,将其中一个置为M状态,另一个置为I状态,且I状态的缓存行修改无效)
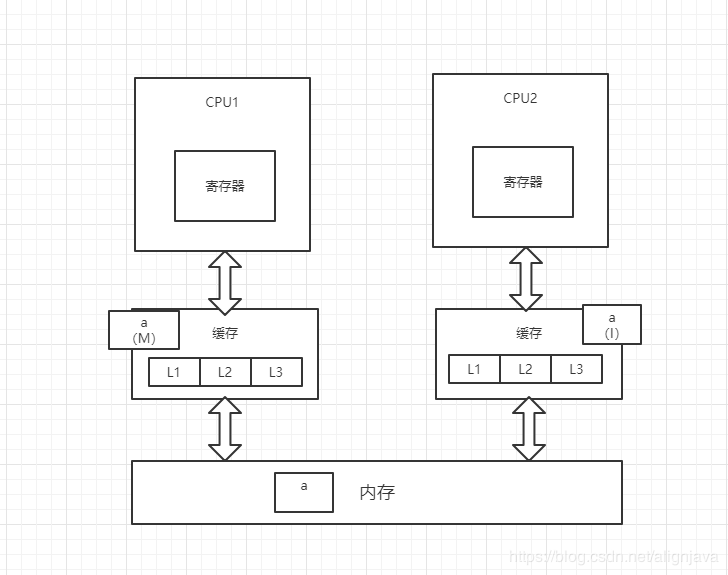
4、CPU1将修改后的数据写回内存,并将变量a置为E(独占)状态
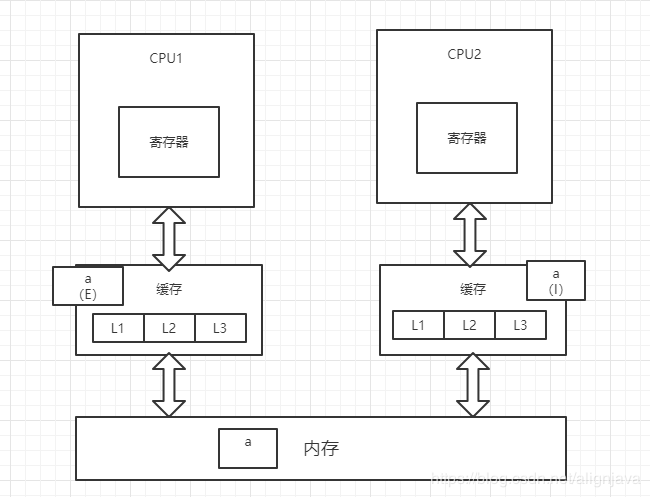
5、此时,CPU2通过总线嗅探机制得知变量a已被修改,会重新去内存中加载变量a,同时CPU1和CPU2中的变量a都改为S状态
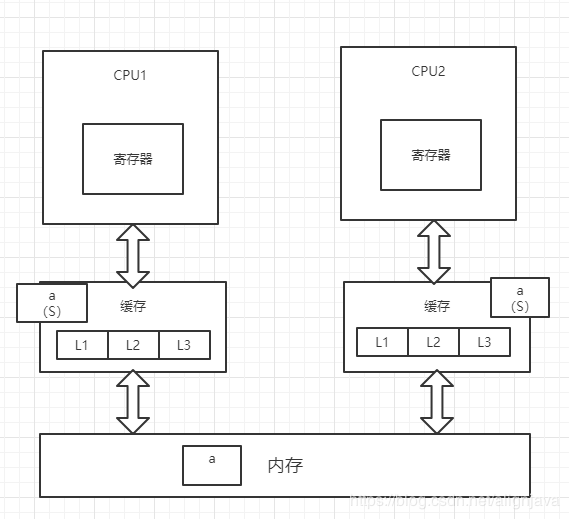
在上述过程第3步中,CPU2的变量a被置为I(无效)状态后,只是保证变量a的修改不会被写回内存,但CPU2有可能会在CPU1将变量a置为E(独占)状态之前重新读取内存中的变量a,这个取决于汇编指令是否要求CPU2重新加载内存。
总结
以上就是MESI的执行原理,MESI协议只能保证并发编程中的可见性,并未解决原子性和有序性的问题,所以只靠MESI协议是无法完全解决多线程中的所有问题。
版权声明:本文为CSDN博主「生煮鸡蛋」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/alignjava/article/details/99070162
