





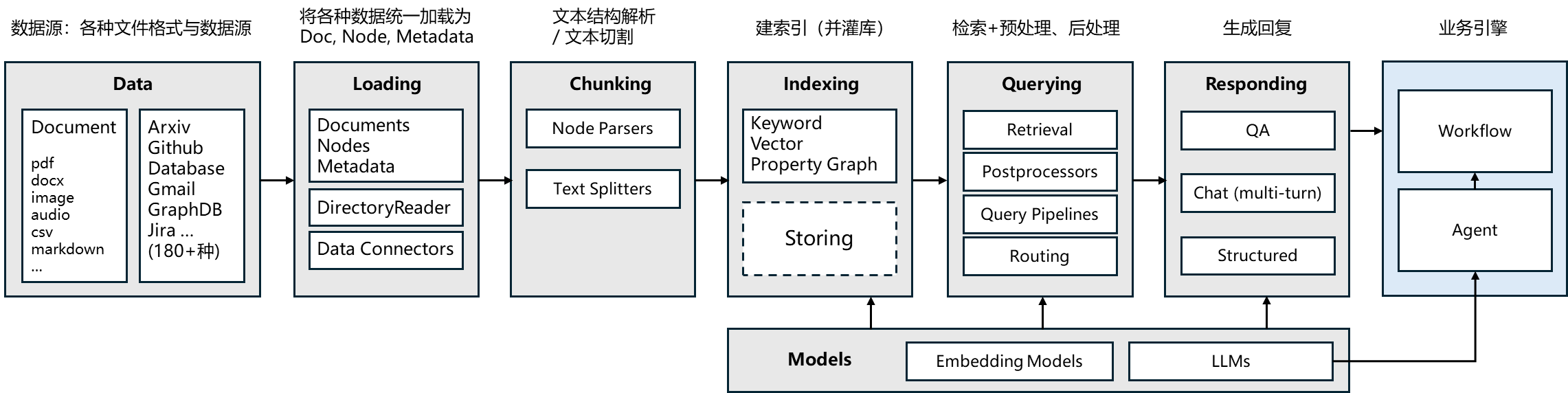
LlamaIndex(曾用名 GPT Index)是一款专为大语言模型(LLM)打造的检索增强生成(RAG)开发框架,简单说:它是连接「你的私有数据(文档 / 数据库 / API)」和「通用 LLM(如 GPT-4 / 通义千问 / Llama)」的 “桥梁”,让 LLM 能精准回答基于你私有数据的问题,而不是只依赖模型自身的训练数据。
1. 大语言模型开发框架的价值是什么?
SDK:Software Development Kit,它是一组软件工具和资源的集合,旨在帮助开发者创建、测试、部署和维护应用程序或软件。
所有开发框架(SDK)的核心价值,都是降低开发、维护成本。
大语言模型开发框架的价值,是让开发者可以更方便地开发基于大语言模型的应用。主要提供两类帮助:
- 第三方能力抽象。比如 LLM、向量数据库、搜索接口等
- 常用工具、方案封装
- 底层实现封装。比如流式接口、超时重连、异步与并行等
好的开发框架,需要具备以下特点:
- 可靠性、鲁棒性高
- 可维护性高
- 可扩展性高
- 学习成本低
举些通俗的例子:
- 与外部功能解依赖
- 比如可以随意更换 LLM 而不用大量重构代码
- 更换三方工具也同理
- 经常变的部分要在外部维护而不是放在代码里
- 比如 Prompt 模板
- 各种环境下都适用
- 比如线程安全
- 方便调试和测试
- 至少要能感觉到用了比不用方便吧
- 合法的输入不会引发框架内部的报错
划重点:选对了框架,事半功倍;反之,事倍功半。
2、LlamaIndex的简单使用
LlamaIndex 是一个为开发「知识增强」的大语言模型应用的框架(也就是 SDK)。知识增强,泛指任何在私有或特定领域数据基础上应用大语言模型的情况。
1、几行代码用LlamaIndex实现一个简单的RPG
先用conda建个环境
conda create -n llama-index python=3.11conda activate llama-index
简单的GPG
运行前需要安装依赖
pip install --upgrade llama-index llama-index-llms-dashscope llama-index-llms-openai-like llama-index-embeddings-dashscope
import osfrom llama_index.core import Settingsfrom llama_index.llms.openai_like import OpenAILikefrom llama_index.llms.dashscope import DashScope, DashScopeGenerationModelsfrom llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModelsfrom llama_index.core import VectorStoreIndex, SimpleDirectoryReader# LlamaIndex默认使用的大模型被替换为百炼# Settings.llm = OpenAILike(# model="qwen-max",# api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",# api_key=os.getenv("DASHSCOPE_API_KEY"),# is_chat_model=True# )Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))# LlamaIndex默认使用的Embedding模型被替换为百炼的Embedding模型Settings.embed_model = DashScopeEmbedding(# model_name="text-embedding-v1"model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1,# api_key=os.getenv("DASHSCOPE_API_KEY"))documents = SimpleDirectoryReader("G:\\AI\\workspace\\data").load_data()index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()response = query_engine.query("deepseek v3有多少参数?")print(response)
3、LlamaIndex的相关组件使用
3.1、加载本地数据
SimpleDirectoryReader 是一个简单的本地文件加载器。它会遍历指定目录,并根据文件扩展名自动加载文件(文本内容)。
支持的文件类型:
.csv- comma-separated values.docx- Microsoft Word.epub- EPUB ebook format.hwp- Hangul Word Processor.ipynb- Jupyter Notebook.jpeg,.jpg- JPEG image.mbox- MBOX email archive.md- Markdown.mp3,.mp4- audio and video.pdf- Portable Document Format.png- Portable Network Graphics.ppt,.pptm,.pptx- Microsoft PowerPoint
import jsonfrom pydantic.v1 import BaseModelfrom llama_index.core import SimpleDirectoryReaderfrom llama_cloud_services import LlamaParsefrom llama_index.core import SimpleDirectoryReaderimport nest_asynciodef show_json(data):"""用于展示json数据"""if isinstance(data, str):obj = json.loads(data)print(json.dumps(obj, indent=4, ensure_ascii=False))elif isinstance(data, dict) or isinstance(data, list):print(json.dumps(data, indent=4, ensure_ascii=False))elif issubclass(type(data), BaseModel):print(json.dumps(data.dict(), indent=4, ensure_ascii=False))def show_list_obj(data):"""用于展示一组对象"""if isinstance(data, list):for item in data:show_json(item)else:raise ValueError("Input is not a list")def queryInfo1():reader = SimpleDirectoryReader(input_dir="G:\\AI\\workspace\\data", # 目标目录recursive=False, # 是否递归遍历子目录required_exts=[".pdf"] # (可选)只读取指定后缀的文件)documents = reader.load_data()print(documents[0].text)show_json(documents[0].json())def queryInfo2():# set up parserparser = LlamaParse(result_type="markdown" # "markdown" and "text" are available)file_extractor = {".pdf": parser}documents = SimpleDirectoryReader(input_dir="G:\\AI\\workspace\\data", required_exts=[".pdf"], file_extractor=file_extractor).load_data()print(documents[0].text)# 程序入口:只有直接运行这个文件时,才执行游戏if __name__ == "__main__":queryInfo2();
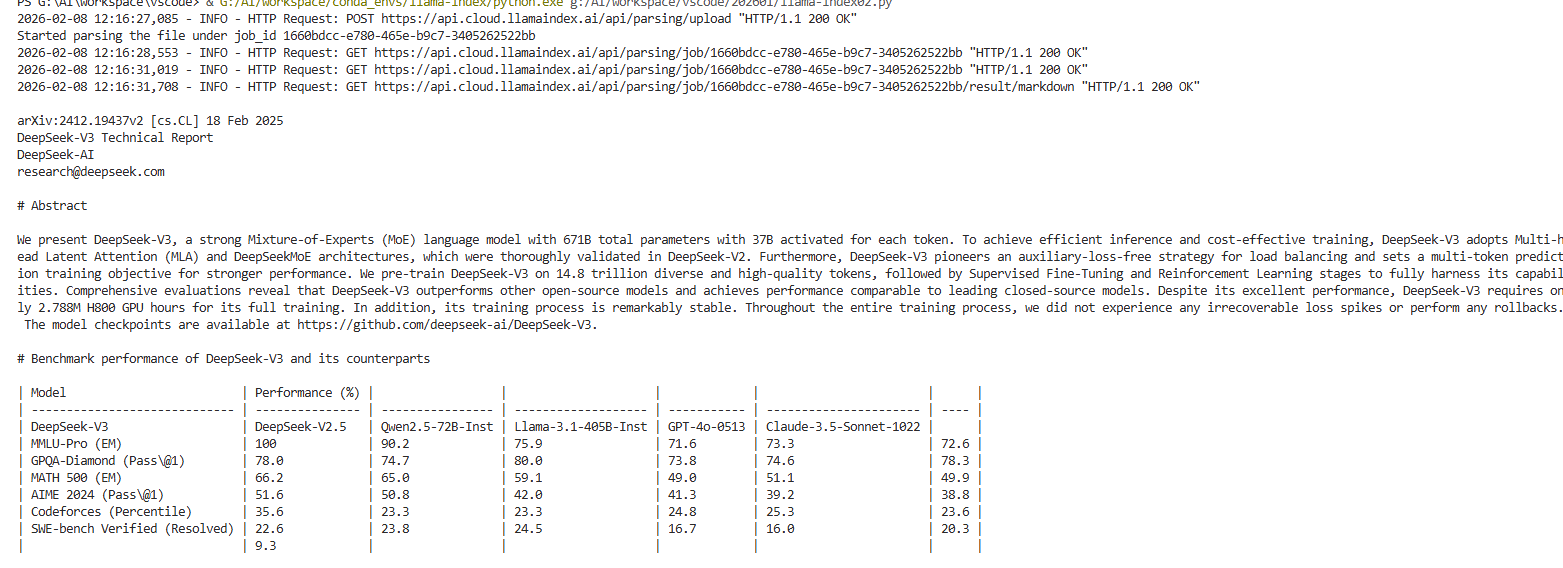
上面的queryInfo2用了LlamaParse,这个对pdf的加载比较友好,执行queryInfo2()需要去https://cloud.llamaindex.ai ↗ 注册并获取 api-key ,然后设置环境变量LLAMA_CLOUD_API_KEY,这里设置完环境变量后记得重启vscode才有效,然后再安装依赖pip install llama-cloud-services,最终运行结果如下,pdf中的表格会读取为较为标准的格式。
3.2、加载远程数据
用于处理更丰富的数据类型,并将其读取为 Document 的形式。
例如:直接读取网页
from llama_index.readers.web import SimpleWebPageReaderdef queryInfo3():documents = SimpleWebPageReader(html_to_text=True).load_data(["https://www.suibibkc.com"])print(documents[0].text)# 程序入口:只有直接运行这个文件时,才执行游戏if __name__ == "__main__":queryInfo3();
3.3、使用 TextSplitters 对文本做切分
例如:TokenTextSplitter 按指定 token 数切分文本
from llama_index.core import Documentfrom llama_index.core.node_parser import TokenTextSplitternode_parser = TokenTextSplitter(chunk_size=512, # 每个 chunk 的最大长度chunk_overlap=200 # chunk 之间重叠长度)nodes = node_parser.get_nodes_from_documents(documents, show_progress=False)show_json(nodes[1].json())show_json(nodes[2].json())
LlamaIndex 提供了丰富的 TextSplitter,例如:
SentenceSplitter:在切分指定长度的 chunk 同时尽量保证句子边界不被切断;CodeSplitter:根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;SemanticSplitterNodeParser:根据语义相关性对将文本切分为片段。
3.4、使用 NodeParsers 对有结构的文档做解析
例如:HTMLNodeParser解析 HTML 文档
from llama_index.core.node_parser import HTMLNodeParserfrom llama_index.readers.web import SimpleWebPageReaderdocuments = SimpleWebPageReader(html_to_text=False).load_data(["https://www.suibibk.com/"])# 默认解析 ["p", "h1", "h2", "h3", "h4", "h5", "h6", "li", "b", "i", "u", "section"]parser = HTMLNodeParser(tags=["span"]) # 可以自定义解析哪些标签nodes = parser.get_nodes_from_documents(documents)for node in nodes:print(node.text+"\n")
更多的 NodeParser 包括 MarkdownNodeParser,JSONNodeParser等等。
3.5、向量检索
VectorStoreIndex直接在内存中构建一个 Vector Store 并建索引
基础概念:在「检索」相关的上下文中,「索引」即index, 通常是指为了实现快速检索而设计的特定「数据结构」。
索引的具体原理与实现不是本课程的教学重点,感兴趣的同学可以参考:传统索引、向量索引
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.core.node_parser import TokenTextSplitter, SentenceSplitter# 加载 pdf 文档documents = SimpleDirectoryReader("./data",required_exts=[".pdf"],).load_data()# 定义 Node Parsernode_parser = TokenTextSplitter(chunk_size=512, chunk_overlap=200)# 切分文档nodes = node_parser.get_nodes_from_documents(documents)# 构建 index,默认是在内存中index = VectorStoreIndex(nodes)# 另外一种实现方式# index = VectorStoreIndex.from_documents(documents=documents, transformations=[SentenceSplitter(chunk_size=512)])# 写入本地文件# index.storage_context.persist(persist_dir="./doc_emb")# 获取 retrievervector_retriever = index.as_retriever(similarity_top_k=2 # 返回2个结果)# 检索results = vector_retriever.retrieve("deepseek v3数学能力怎么样?")print(results[0].text)
使用自定义的 Vector Store,以 Qdrant 为例:
pip install llama-index-vector-stores-qdrant
from llama_index.core.indices.vector_store.base import VectorStoreIndexfrom llama_index.vector_stores.qdrant import QdrantVectorStorefrom llama_index.core import StorageContextfrom qdrant_client import QdrantClientfrom qdrant_client.models import VectorParams, Distanceclient = QdrantClient(location=":memory:")collection_name = "demo"collection = client.create_collection(collection_name=collection_name,vectors_config=VectorParams(size=1536, distance=Distance.COSINE))vector_store = QdrantVectorStore(client=client, collection_name=collection_name)# storage: 指定存储空间storage_context = StorageContext.from_defaults(vector_store=vector_store)# 创建 index:通过 Storage Context 关联到自定义的 Vector Storeindex = VectorStoreIndex(nodes, storage_context=storage_context)# 获取 retrievervector_retriever = index.as_retriever(similarity_top_k=1)# 检索results = vector_retriever.retrieve("deepseek v3数学能力怎么样")print(results[0])
更多索引与检索方式
LlamaIndex 内置了丰富的检索机制,例如:
关键字检索
BM25Retriever:基于 tokenizer 实现的 BM25 经典检索算法KeywordTableGPTRetriever:使用 GPT 提取检索关键字KeywordTableSimpleRetriever:使用正则表达式提取检索关键字KeywordTableRAKERetriever:使用RAKE算法提取检索关键字(有语言限制)
RAG-Fusion
QueryFusionRetriever还支持 KnowledgeGraph、SQL、Text-to-SQL 等等
3.6、检索后处理
LlamaIndex 的 Node Postprocessors 提供了一系列检索后处理模块。
例如:我们可以用不同模型对检索后的 Nodes 做重排序
# 获取 retrievervector_retriever = index.as_retriever(similarity_top_k=5)# 检索nodes = vector_retriever.retrieve("deepseek v3有多少参数?")for i, node in enumerate(nodes):print(f"[{i}] {node.text}\n")
重排序
from llama_index.core.postprocessor import LLMRerankpostprocessor = LLMRerank(top_n=2)nodes = postprocessor.postprocess_nodes(nodes, query_str="deepseek v3有多少参数?")for i, node in enumerate(nodes):print(f"[{i}] {node.text}")
更多的 Rerank 及其它后处理方法,参考官方文档:Node Postprocessor Modules
3.7. 生成回复(QA & Chat)
import osfrom llama_index.core import Settingsfrom llama_index.llms.openai_like import OpenAILikefrom llama_index.llms.dashscope import DashScope, DashScopeGenerationModelsfrom llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModelsfrom llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.core.postprocessor import LLMRerank# LlamaIndex默认使用的大模型被替换为百炼# Settings.llm = OpenAILike(# model="qwen-max",# api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",# api_key=os.getenv("DASHSCOPE_API_KEY"),# is_chat_model=True# )Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))# LlamaIndex默认使用的Embedding模型被替换为百炼的Embedding模型Settings.embed_model = DashScopeEmbedding(# model_name="text-embedding-v1"model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1,# api_key=os.getenv("DASHSCOPE_API_KEY"))documents = SimpleDirectoryReader("G:\\AI\\workspace\\data").load_data()index = VectorStoreIndex.from_documents(documents)'''# 获取 retrievervector_retriever = index.as_retriever(similarity_top_k=5)# 检索nodes = vector_retriever.retrieve("deepseek v3有多少参数?")for i, node in enumerate(nodes):print(f"[{i}] {node.text}\n")#对检索结果进行重排序postprocessor = LLMRerank(top_n=2)nodes = postprocessor.postprocess_nodes(nodes, query_str="deepseek v3有多少参数?")for i, node in enumerate(nodes):print(f"[{i}] {node.text}\n")#流式输出qa_engine = index.as_query_engine(streaming=True)response = qa_engine.query("deepseek v3数学能力怎么样?")response.print_response_stream()#多轮对话chat_engine = index.as_chat_engine()response = chat_engine.chat("deepseek v3数学能力怎么样?")print(response)#会记住上下文response = chat_engine.chat("代码能力呢?")print(response)'''#多轮对话流式输出chat_engine = index.as_chat_engine()streaming_response = chat_engine.stream_chat("deepseek v3数学能力怎么样?")# streaming_response.print_response_stream()for token in streaming_response.response_gen:print(token, end="", flush=True)
3.8. Prompt
from llama_index.core import PromptTemplatefrom llama_index.core.llms import ChatMessage, MessageRolefrom llama_index.core import ChatPromptTemplateimport osfrom llama_index.core import Settingsfrom llama_index.llms.openai_like import OpenAILikefrom llama_index.llms.dashscope import DashScope, DashScopeGenerationModelsfrom llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModelsfrom llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.core.postprocessor import LLMRerankfrom llama_index.llms.deepseek import DeepSeekdef queryInfo1():prompt = PromptTemplate("写一个关于{topic}的笑话")print(prompt.format(topic="小明"))def queryInfo2():chat_text_qa_msgs = [ChatMessage(role=MessageRole.SYSTEM,content="你叫{name},你必须根据用户提供的上下文回答问题。",),ChatMessage(role=MessageRole.USER,content=("已知上下文:\n" \"{context}\n\n" \"问题:{question}")),]text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)print(text_qa_template.format(name="小明",context="这是一个测试",question="这是什么"))def queryInfo3():Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))chat_text_qa_msgs = [ChatMessage(role=MessageRole.SYSTEM,content="你叫{name},你必须根据用户提供的上下文回答问题。",),ChatMessage(role=MessageRole.USER,content=("已知上下文:\n" \"{context}\n\n" \"问题:{question}")),]text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)response = Settings.llm.complete(text_qa_template.format(name="小明",context="这是一个测试",question="你是谁,我们在干嘛"))print(response.text)if __name__ == "__main__":queryInfo3();
4. 基于 LlamaIndex 实现一个功能较完整的 RAG 系统
pip install qdrant-clientpip install llama-index llama-index-vector-stores-qdrant
例子
import osfrom qdrant_client import QdrantClientfrom qdrant_client.models import VectorParams, Distancefrom llama_index.core import VectorStoreIndex, SimpleDirectoryReader, get_response_synthesizerfrom llama_index.vector_stores.qdrant import QdrantVectorStorefrom llama_index.core.node_parser import SentenceSplitterfrom llama_index.core.response_synthesizers import ResponseModefrom llama_index.core.ingestion import IngestionPipelinefrom llama_index.core import Settingsfrom llama_index.core import StorageContextfrom llama_index.core.postprocessor import LLMRerank, SimilarityPostprocessorfrom llama_index.core.retrievers import QueryFusionRetrieverfrom llama_index.core.query_engine import RetrieverQueryEnginefrom llama_index.core.chat_engine import CondenseQuestionChatEnginefrom llama_index.llms.dashscope import DashScope, DashScopeGenerationModelsfrom llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModelsEMBEDDING_DIM = 1536COLLECTION_NAME = "full_demo"PATH = "./qdrant_db"client = QdrantClient(path=PATH)# 1. 指定全局llm与embedding模型Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX,api_key=os.getenv("DASHSCOPE_API_KEY"))Settings.embed_model = DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)# 2. 指定全局文档处理的 Ingestion PipelineSettings.transformations = [SentenceSplitter(chunk_size=512, chunk_overlap=200)]# 3. 加载本地文档documents = SimpleDirectoryReader("G:\\AI\\workspace\\data").load_data()if client.collection_exists(collection_name=COLLECTION_NAME):client.delete_collection(collection_name=COLLECTION_NAME)# 4. 创建 collectionclient.create_collection(collection_name=COLLECTION_NAME,vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE))# 5. 创建 Vector Storevector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME)# 6. 指定 Vector Store 的 Storage 用于 indexstorage_context = StorageContext.from_defaults(vector_store=vector_store)index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)# 最终打分低于0.6的文档被过滤掉sp = SimilarityPostprocessor(similarity_cutoff=0.6)# 7. 定义检索后排序模型reranker = LLMRerank(top_n=2)# 8. 定义 RAG Fusion 检索器fusion_retriever = QueryFusionRetriever([index.as_retriever()],similarity_top_k=5, # 检索召回 top k 结果num_queries=3, # 生成 query 数use_async=False,# query_gen_prompt="", # 可以自定义 query 生成的 prompt 模板)# 9. 构建单轮 query enginequery_engine = RetrieverQueryEngine.from_args(fusion_retriever,# 处理器执行顺序:先过滤低相似度文档,再做LLM重排node_postprocessors=[sp,reranker],response_synthesizer=get_response_synthesizer(response_mode = ResponseMode.REFINE))# 10. 对话引擎chat_engine = CondenseQuestionChatEngine.from_defaults(query_engine=query_engine,# condense_question_prompt="" # 可以自定义 chat message prompt 模板)# 测试多轮对话# User: deepseek v3有多少参数# User: 每次激活多少while True:question=input("User:")if question.strip() == "":breakresponse = chat_engine.chat(question)print(f"AI: {response}")
5、基于LlamaIndex实现一个中医临床诊疗的例子
import reimport loggingimport sysimport osfrom llama_index.core import PromptTemplate, Settings, SimpleDirectoryReader, VectorStoreIndex, load_index_from_storage, StorageContext, QueryBundlefrom llama_index.core.schema import MetadataModefrom llama_index.core.node_parser import SentenceSplitterfrom llama_index.llms.dashscope import DashScope, DashScopeGenerationModelsfrom llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModelsfrom llama_index.core.callbacks import LlamaDebugHandler, CallbackManagerfrom llama_index.core.indices.vector_store import VectorIndexRetrieverfrom llama_index.core.query_engine import RetrieverQueryEnginefrom llama_index.core.response_synthesizers import ResponseModefrom llama_index.core import get_response_synthesizerfrom llama_index.core.postprocessor import SimilarityPostprocessor# 定义日志配置logging.basicConfig(stream=sys.stdout, level=logging.INFO)logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))#指定全局llm与embedding模型Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX,api_key=os.getenv("DASHSCOPE_API_KEY"))Settings.embed_model = DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)def remove_english(input_file, output_file):"""去除文件中所有英文字符并生成新文件:param input_file: 输入文件路径:param output_file: 输出文件路径"""try:with open(input_file, 'r', encoding='utf-8') as f_in:content = f_in.read()# 使用正则表达式移除所有英文字母filtered_content = re.sub('[A-Za-z/]', '', content)with open(output_file, 'w', encoding='utf-8') as f_out:f_out.write(filtered_content)print(f"处理完成,已生成新文件:{output_file}")except Exception as e:print(f"处理出错:{str(e)}")def createEmbedding():# 读取文档documents = SimpleDirectoryReader("G:\\AI\workspace\\data\\", required_exts=[".txt"]).load_data()#对文档进行切分,将切分后的片段转化为embedding向量,构建向量索引index = VectorStoreIndex.from_documents(documents, transformations=[SentenceSplitter(chunk_size=256)])# 将embedding向量和向量索引存储到文件中# ./doc_emb 是存储路径index.storage_context.persist(persist_dir='G:\\AI\\workspace\\vscode\\db\\doc_emb')print("构建向量数据库完成")def queryInfo(query:str):# 使用LlamaDebugHandler构建事件回溯器,以追踪LlamaIndex执行过程中发生的事件llama_debug = LlamaDebugHandler(print_trace_on_end=True)callback_manager = CallbackManager([llama_debug])Settings.callback_manager = callback_manager# 从存储文件中读取embedding向量和向量索引storage_context = StorageContext.from_defaults(persist_dir="G:\\AI\\workspace\\vscode\\db\\doc_emb")# 根据存储的embedding向量和向量索引重新构建检索索引index = load_index_from_storage(storage_context)#构建查询引擎# streaming 流式输出# similarity_top_k 检索结果的数量query_engine = index.as_query_engine(streaming=True, similarity_top_k=5)#追踪哪些文档片段被检索# 获取我们抽取出的相似度 top 5 的片段contexts = query_engine.retrieve(QueryBundle(query))print('-' * 10 + 'ref' + '-' * 10)for i, context in enumerate(contexts):print('#' * 10 + f'chunk {i} start' + '#' * 10)content = context.node.get_content(metadata_mode=MetadataMode.LLM)print(content)print('#' * 10 + f'chunk {i} end' + '#' * 10)print('-' * 10 + 'ref' + '-' * 10)#生成答案response = query_engine.query(query)#流式输出#response.print_response_stream()print(response)# get_llm_inputs_outputs 返回每个LLM调用的开始/结束事件event_pairs = llama_debug.get_llm_inputs_outputs()print("------------------")#打印详细的执行过程#print(event_pairs)#自定义retriever和一种response synthesizerdef queryInfo2(query:str):# 从存储文件中读取embedding向量和向量索引storage_context = StorageContext.from_defaults(persist_dir="G:\\AI\\workspace\\vscode\\db\\doc_emb")# 根据存储的embedding向量和向量索引重新构建检索索引index = load_index_from_storage(storage_context)# 构建retrieverretriever = VectorIndexRetriever(index = index,similarity_top_k = 5,)# 构建response synthesizerresponse_synthesizer = get_response_synthesizer(response_mode = ResponseMode.REFINE)# 构建查询引擎query_engine = RetrieverQueryEngine(retriever = retriever,response_synthesizer = response_synthesizer,node_postprocessors = [SimilarityPostprocessor(similarity_cutoff=0.6)])#生成答案response = query_engine.query(query)#流式输出#response.print_response_stream()print(response)#自定义 Promptdef queryInfo3(query:str):# 定义qa promptqa_prompt_tmpl_str = ("上下文信息如下。\n""---------------------\n""{context_str}\n""---------------------\n""请根据上下文信息而不是先验知识来回答以下的查询。""作为一个医疗人工智能助手,你的回答要尽可能严谨。\n""Query: {query_str}\n""Answer: ")qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str)# 定义refine promptrefine_prompt_tmpl_str = ("原始查询如下:{query_str}""我们提供了现有答案:{existing_answer}""我们有机会通过下面的更多上下文来完善现有答案(仅在需要时)。""------------""{context_msg}""------------""考虑到新的上下文,优化原始答案以更好地回答查询。 如果上下文没有用,请返回原始答案。""Refined Answer:")refine_prompt_tmpl = PromptTemplate(refine_prompt_tmpl_str)# 从存储文件中读取embedding向量和向量索引storage_context = StorageContext.from_defaults(persist_dir="G:\\AI\\workspace\\vscode\\db\\doc_emb")# 根据存储的embedding向量和向量索引重新构建检索索引index = load_index_from_storage(storage_context)# 构建查询引擎query_engine = index.as_query_engine(similarity_top_k=5)# 更新查询引擎中的prompt templatequery_engine.update_prompts({"response_synthesizer:text_qa_template": qa_prompt_tmpl,"response_synthesizer:refine_template": refine_prompt_tmpl})#生成答案response = query_engine.query(query)#流式输出#response.print_response_stream()print(response)# 使用示例if __name__ == "__main__":#remove_english('G:\\AI\workspace\\data\\demo.txt', 'G:\\AI\workspace\\data\\demo-1.txt')#createEmbedding()queryInfo("不耐疲劳,口燥、咽干可能是哪些证候?");#queryInfo2("不耐疲劳,口燥、咽干可能是哪些证候?");#queryInfo3("不耐疲劳,口燥、咽干可能是哪些证候?");
上面需要补充说明的知识点如下
SentenceSplitter 参数详细设置
预设会以 1024 个 token 为界切割片段, 每个片段的开头重叠上一个片段的 200 个 token 的内容。
chunk_size = 1024, # 切片 token 数限制chunk_overlap = 200, # 切片开头与前一片段尾端的重复 token 数paragraph_separator = '\n\n\n', # 段落的分界secondary_chunking_regex = '[^,.;。?!]+[,.;。?!]?' # 单一句子的样式separator = ' ', # 最小切割的分界字元
追踪检索片段
追踪检索片段,调整chunk_size的值,可以让embedding模型切分出的片段更合理,提高RAG系统的表现。
如果想追踪更多的检索片段,可以提高 similarity_top_k 的值。
如果想追踪片段具体的相似度得分(Similarity Score)的值,可以将log中的level设置为DEBUG级别。
Query 过程分析
**********Trace: query|_CBEventType.QUERY -> 0.866733 seconds|_CBEventType.RETRIEVE -> 0.866733 seconds|_CBEventType.EMBEDDING -> 0.766721 seconds|_CBEventType.SYNTHESIZE -> 0.0 seconds|_CBEventType.TEMPLATING -> 0.0 seconds|_CBEventType.LLM -> 0.0 seconds**********
貌似打印结果不符合预期,我明明等了二十秒
Retrieve 检索进阶
抽取(retrieve)阶段的retrievers模块规定了针对查询从知识库获取相关上下文的技术。我们之前使用的都是默认的方法,其实LlamaIndex官方为我们提供了一些其他常用的方法:
- SimilarityPostprocessor: 使用similarity_cutoff设置阈值。移除低于某个相似度分数的节点。
- KeywordNodePostprocessor: 使用required_keywords和exclude_keywords。根据关键字包含或排除过滤节点。
- MetadataReplacementPostProcessor: 用其元数据中的数据替换节点内容。
- LongContextReorder: 重新排序节点,这有利于需要大量顶级结果的情况,可以解决模型在扩展上下文中的困难。
- SentenceEmbeddingOptimizer: 选择percentile_cutoff或threshold_cutoff作为相关性。基于嵌入删除不相关的句子。
- CohereRerank: 使用coherence ReRank对节点重新排序,返回前N个结果。
- SentenceTransformerRerank: 使用SentenceTransformer交叉编码器对节点重新排序,产生前N个节点。
- LLMRerank: 使用LLM对节点重新排序,为每个节点提供相关性评分。
- FixedRecencyPostprocessor: 返回按日期排序的节点。
- EmbeddingRecencyPostprocessor: 按日期对节点进行排序,但也会根据嵌入相似度删除较旧的相似节点。
- TimeWeightedPostprocessor: 对节点重新排序,偏向于最近未返回的信息。
- PIINodePostprocessor(β): 可以利用本地LLM或NER模型删除个人身份信息。
- PrevNextNodePostprocessor(β): 根据节点关系,按顺序检索在节点之前、之后或两者同时出现的节点
响应合成器 response synthesizer
合成(synthesize)阶段的响应合成器(response synthesizer)会引导LLM生成响应,将用户查询与检索到的文本块混合在一起,并给出一个精心设计的答案。
LlamaIndex官方为我们提供了多种响应合成器:
- Refine: 这种方法遍历每一段文本,一点一点地精炼答案。
- Compact: 是Refine的精简版。它将文本集中在一起,因此需要处理的步骤更少。
- Tree Summarize: 想象一下,把许多小的答案结合起来,再总结,直到你得到一个主要的答案。
- Simple Summarize: 只是把文本片段剪短,然后给出一个快速的总结。
- No Text: 这个问题不会给你答案,但会告诉你它会使用哪些文本。
- Accumulate: 为每一篇文章找一堆小答案,然后把它们粘在一起。
- Compact Accumulate: 是“Compact”和“Accumulate”的合成词。
现在,我们选择一种retriever和一种response synthesizer。retriever选择SimilarityPostprocessor,response synthesizer选择Refine。
RAG 系统评估
评估的例子我们可以把文档给大模型,让大模型给我们自动生成一批问答对
